社会人博士を始めるにあたり、画像のセマンティックセグメンテーションについてまとめました。
体験談も書いているので、よければそちらもご覧ください。
画像認識の代表的なタスク
下の図は代表的な画像認識のタスクを表しています。それぞれのタスクの概要は以下の通りです。
Classification: 1枚の写真を見て、それが犬なのか猫なのか、1つのラベルを付与するタスクです。写真のように、猫しか映っていない写真ならいいですが、複数の物体が移っている場合に、あまり現実的なタスクではなくなってしまいます。
Semantic segmentation:今回紹介するタスクです。写真の各ピクセルが、どのクラスにどのクラスに属しているかというのを分類するタスクです。後で詳しく紹介します。
Object detection:日本語では物体検出といいます。各物体がその画像の中で、どこにあるのかをBounding boxという四角で検出し、同時にクラスも分類します。
Instance segmentation:セマンティックセグメンテーションと似ていますが、異なるタスクです。セマンティックセグメンテーションは、クラスのみを表すのに対し、インスタンスセグメンテーションは個体も識別します。一番右の写真には犬が2匹映っていますが、2頭が違う個体であることを識別しています。セマンティックセグメンテーションは識別しません。
その他、最近ではPanoptic segmentationというタスクもFacebookから提案されています。インスタンスセグメンテーションでは、個体の識別はできるものの、背景のセグメンテーションはできません。Panoptic segmentationはセマンティックセグメンテーションとインスタンスセグメンテーションの両方を同時に行うタスクです。

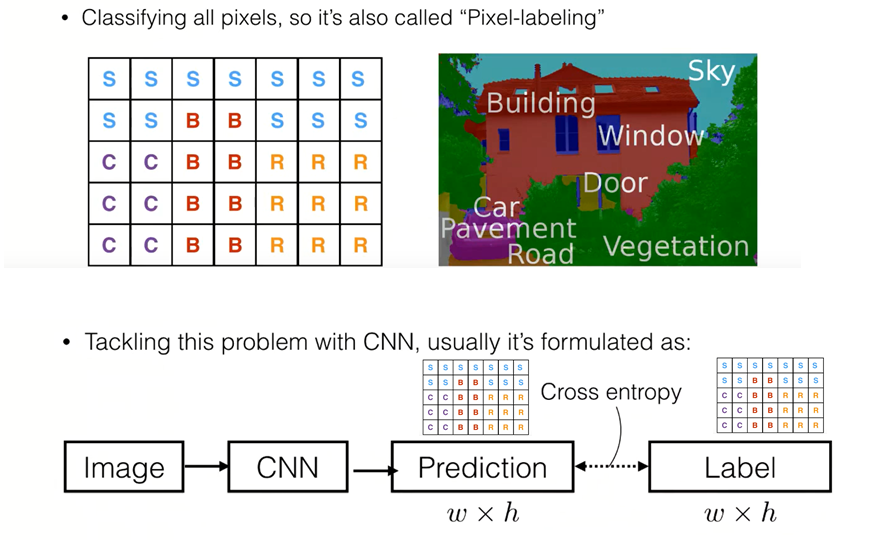
従来のClassificationはどうやっていたか?
では、具体的にどういったネットワークを組めば、セマンティックセグメンテーションができるか。まず前段として、最も単純なタスクである、Classificationはどうやってたかを説明します。
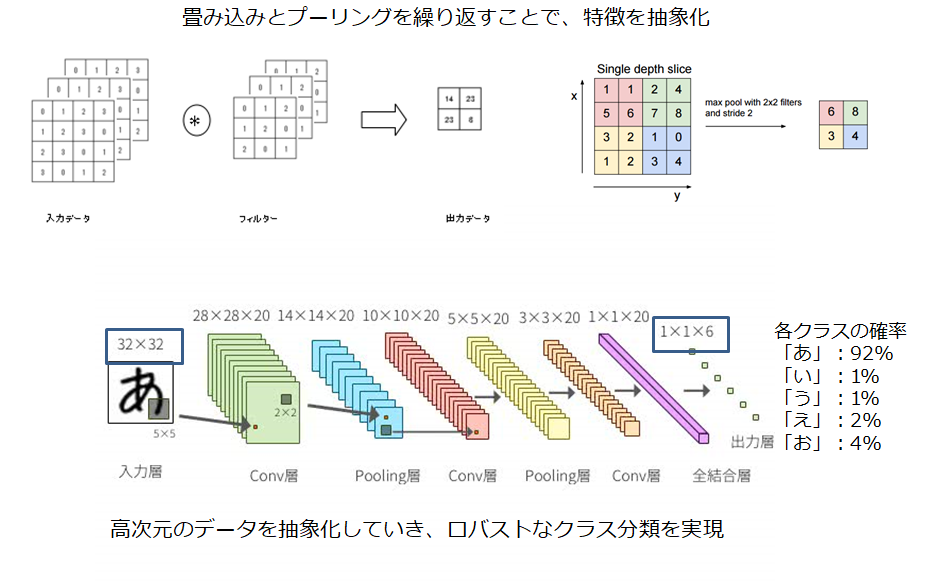
以下は、Convolutional Neural Network(CNN)を用いた、ひらがな認識の例です。
フィルタを用いた畳み込みとプーリング(間引き)を繰り返すことで、画素数の多かった1枚の画像から、抽象的な特徴を抽出していきます。最終的に得られる出力は、最終層の全結合層を経て、それぞれの文字である確率が何%であるかという確率が得られます。下の例では、「あ」である確率が92%であるので、AIはこの画像は「あ」であると判断します。
セマンティックセグメンテーションはどうすればいいか?
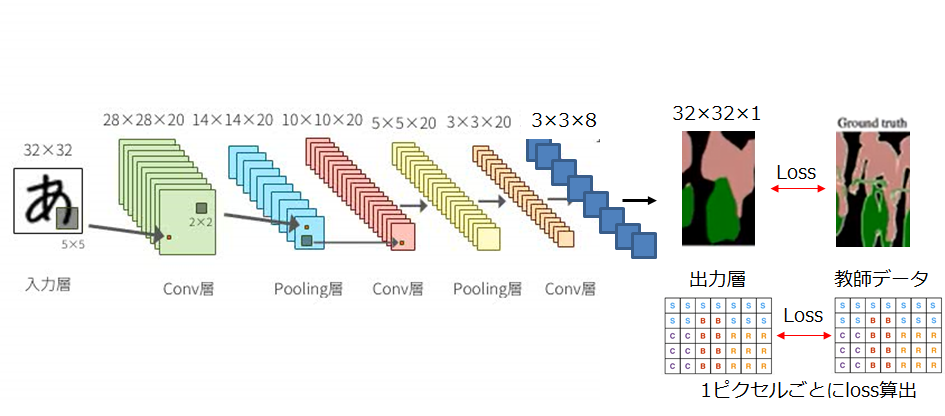
Classificationでは、多すぎるピクセルを抽象化して、少ない変数に落とし込んでいましたが、セマンティックセグメンテーションでは、各ピクセルの情報が知りたいので、元の解像度に戻してやらなければいけません。
そこで、初期に提案されたのがFully Convolutional Network(FCN)と呼ばれる手法です。Classificationでは、最終層の全結合層で、「あ」である確率を求めていましたが、代わりにアップサンプリング(画像の引き延ばし)を行ってしまえばよいのではという発想からできています。
CNNをセグメンテーションに使うことに対する課題と研究方向性
Classificationの手法をそのまま流用すると、どういった課題があるでしょうか。具体的には、以下の2つが主な課題と研究の方向性になっています。
①畳み込み処理では、各ピクセルが独立なものとして扱われてしまう
Classificationでは、最終的に1つのラベルが分かればよいですが、セマンティックセグメンテーションでは、隣通しの関係性(context)も非常に重要です。隣のピクセルが海だったのに、急に車のピクセルになる可能性は低いです。従来のClassifiaction手法よりも広範囲の関係性を効率よく学習できる手法が求められます。
②無理やりアップサンプリングしても、高解像度の画像は得られない
単純にアップサンプリングしていいのでしょうか?想像に難くないと思いますが、抽象化された特徴マップを無理やり引き延ばしても、高解像度の画像は作れません。畳み込みにより、抽象化されてしまった特徴を、どのように高解像度の画像に復元していくかが重要になります。
セマンティックセグメンテーションの課題を解決する手法
ここからは、上述した課題に対し、提案されてきた具体的な手法について紹介していきます。古い方から紹介していきますので、新しい手法だけを知りたい方は読み飛ばしてください。
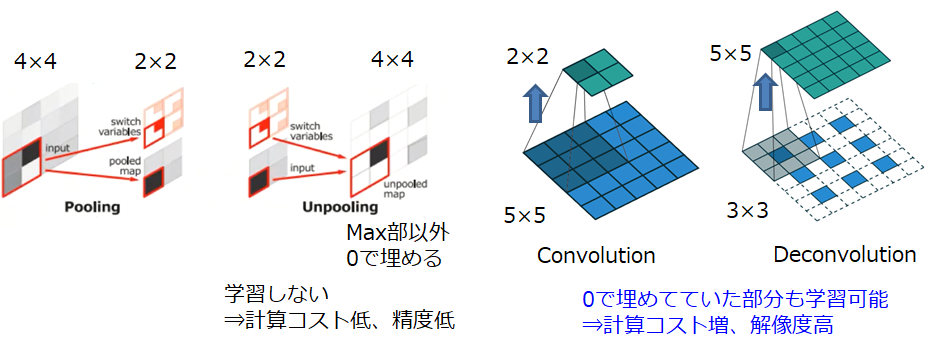
①Deconvolution Network
単純にアップサンプリングするのではなく、解像度を上げるためのフィルタを使用する方法です。Convolutionが画像サイズを小さくしながら特徴抽出を行うのに対し、その反対の操作を行うことから、Deconvolutionと呼ばれています。

Noh, Hyeonwoo, Seunghoon Hong, and Bohyung Han. "Learning deconvolution network for semantic segmentation." Proceedings of the IEEE international conference on computer vision. 2015.
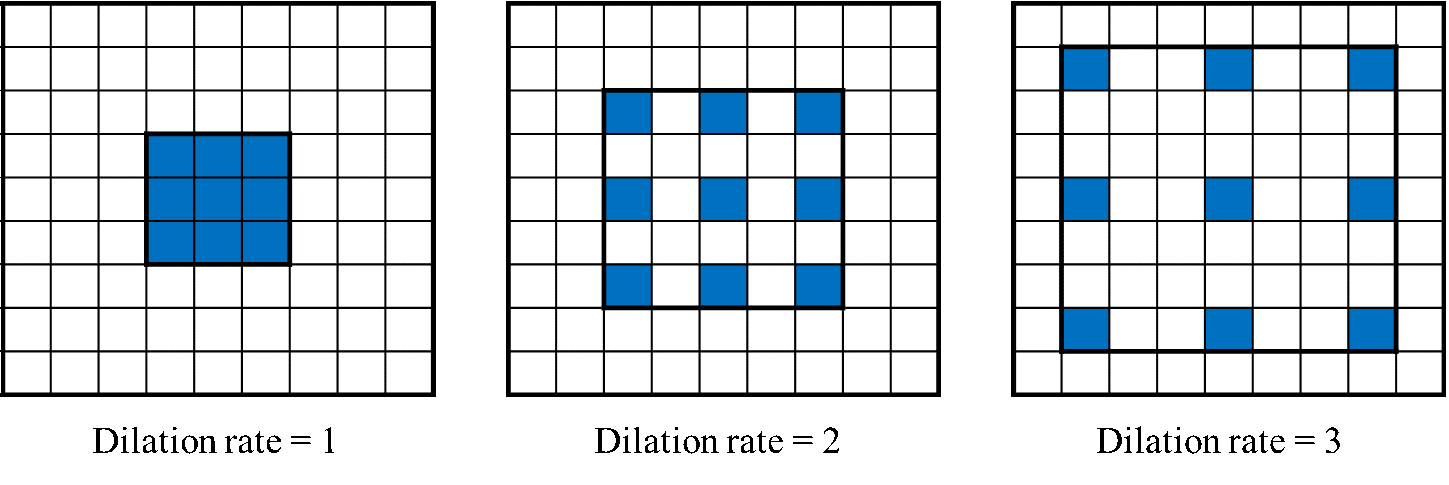
②Dilated convolution
畳み込みのフィルタに工夫を加える手法です。通常の畳み込みでは、以下左のように、小さいフィルタで畳み込みを行うと狭い範囲の特徴しか抽出できません。もちろん、もっと大きなフィルタを使えば、広範囲の特徴抽出は可能ですが、パラメータ数・計算量が爆発してしまいます。そこで、Dilated convolutionは右の図のように、感覚をあけながら畳み込みを行います。これにより、パラメータ数を増やすことなく、より広範囲の特徴抽出が可能になります。
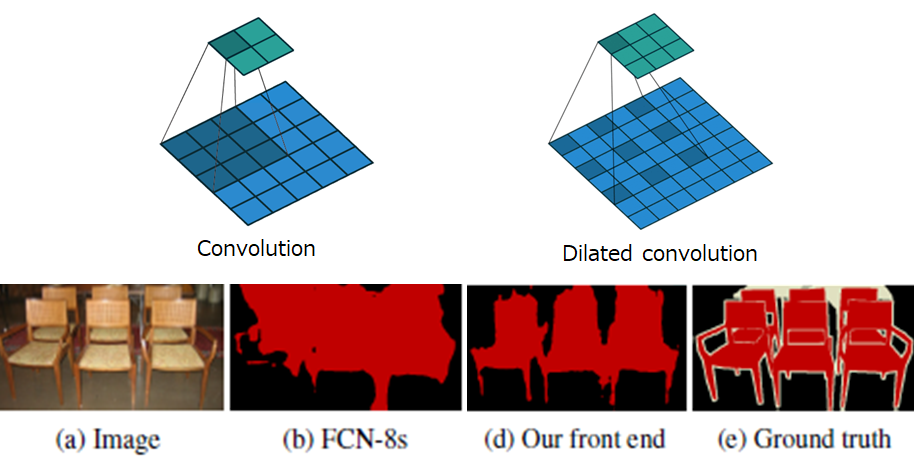
Yu, Fisher, and Vladlen Koltun. "Multi-scale context aggregation by dilated convolutions." arXiv preprint arXiv:1511.07122 (2015).
③U-Net
今となっては、基本中の基本ネットワークになっていますが、シンプルで今でも学会で見ます。①のDeconvolutionも使用しており、ネットワークも似ていますが、それ以外にSkip connectionを持っています。Skip connectionとは、下図左の畳み込み層の各層から、直接Deconvolution層へのスキップ結合をもちます。意図としては、完全に抽象化された特徴から、高解像度の画像を復元するのではなく、抽象化される前の高解像な特徴も使いながら高解像な画像の復元を行ったほうが効率がいいのではという発想から生まれています。
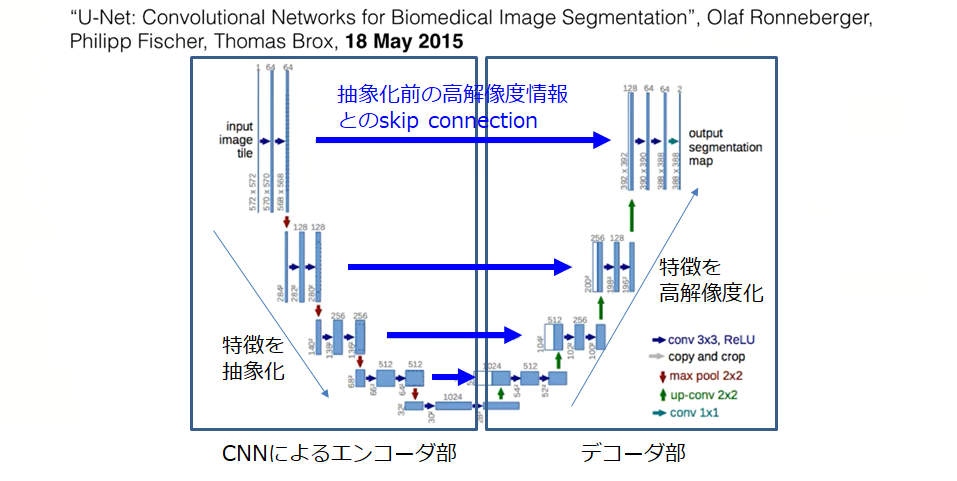
Ronneberger, Olaf, Philipp Fischer, and Thomas Brox. "U-net: Convolutional networks for biomedical image segmentation." International Conference on Medical image computing and computer-assisted intervention. Springer, Cham, 2015.
④Segnet
こちらは、性能向上に効くかどうかは怪しいのですが、当時は、計算時間の短縮を目的に提案されています。具体的には、Deconvolutionの代わりにUnpoolingという手法を用いてアップサンプリングを行っています。
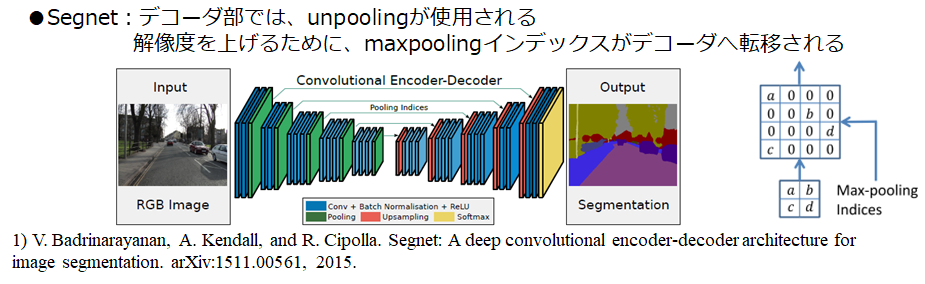
Badrinarayanan, Vijay, Alex Kendall, and Roberto Cipolla. "Segnet: A deep convolutional encoder-decoder architecture for image segmentation." IEEE transactions on pattern analysis and machine intelligence 39.12 (2017): 2481-2495.
⑤PSPNet
このあたりから、性能がかなり上がります。この論文の中で、今までのセマンティックセグメンテーションでは、大きすぎる物体や小さすぎる物体が苦手であることや、湖のシーンなのに車が浮いていると判定したり、その画像のシーンをちゃんと学習できていないことが問題だと主張しています。より広い範囲の関係性を学習するために、ピラミッド構造の畳み込みを提案しています。具体的には、小さなフィルタと大きなフィルタを明示的にネットワークに組み込むことで、小さすぎる物体、大き過ぎる物体、あるいはそのシーン全体の学習を可能にしました。
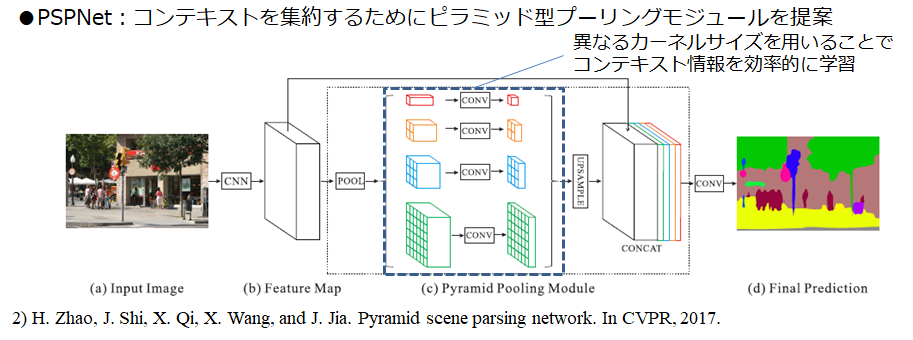
Zhao, Hengshuang, et al. "Pyramid scene parsing network." Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
⑥Deeplabv3+
最後は、Googleの提案したDeeplabv3+です。提案されたのは2018年ですが、2019年現在でも、これを大きく上回るような画期的な手法は出てきていないように思います。こちらもPSPNetと同様にピラミッド構造で、より広い範囲の関係性を学習させることができますが、アプローチが少し異なります。Deeplabv3+では、Atrous Spatial Pyramid Pooling (ASPP)モジュールというものを提案しています。Atrous convolutionとは、呼び方が異なるだけで、②のDilated convolutionと同じものですが、ASPPモジュールでは、そのdilation rateをピラミッド状に変化させています。Dilated convolutionの説明で、飛び飛びの畳み込みフィルタを使うといいましたが、何ピクセル飛ばすかを表すのが、Dilation rateです。このdilation rateを変化させることで、より広範囲の関係性を学習することができます。
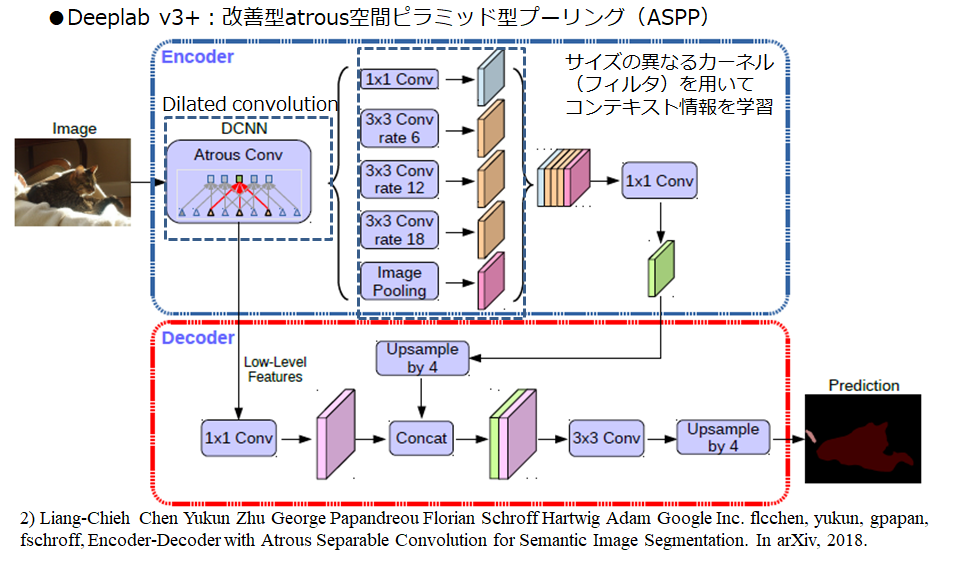
Chen, Liang-Chieh, et al. "Encoder-decoder with atrous separable convolution for semantic image segmentation." Proceedings of the European conference on computer vision (ECCV). 2018.
評価実験
試しに、いくつかの手法を試してみました。パラメータチューニング等はやっていないので、各手法が最適化されているわけではないので、あくまでも傾向比較です。
データセット
以下に示す、Cityscapesというヨーロッパの自動運転用データセットを使用しました。Cityscapesデータセットは細かくアノテーションされたFine annotationsと荒くアノテーションされたCourse annotationの2種類存在しますが、今回はFine annotations5000枚のみを使用しました。

結果
結果は以下の通りです。やはり、Deeplabv3+は一番性能は良さそうです。U-Netはノイズの多い画像になってしまいました。スキップ構造により、特徴の抽出しきれていない高解像な画像を直接スキップしているので、ノイズが乗りやすい可能性があるのではと考えています。

まとめ
・画像を使った代表的なタスクには、クラス分類、物体検出、セグメンテーションがある
・セグメンテーションでは、広範囲のコンテキストの学習・高解像度化の2つの課題が存在
・Deeplabv3+のような、ピラミッド構造やDilated convolutionが提案されている。
また、意外にあまり認識されていないかもしれませんが、セマンティックセグメンテーションのネットワークはは音声データにもよく使われます。
以下の記事では、U-NetをCDを音源のボーカル分離に適用した技術やその他音を使ったディープラーニング技術について解説していますので、よければそちらもご覧ください。