【ロボット関連学会】IROS2019 in Macau 深層学習を用いたロボット技術レポート
2019/11/4-8で開催されたIROSという学会に参加してきたので、自分のまとめも兼ねてまとめていこうと思います。
IROSとは、International Conference on Intelligent Robots and Systemsの略で、ロボットに関する国際会議です。

参加者の推移
年々参加者が増加しており、今年は1130件の論文が採択され、採択率は45%を切っていました。(青:投稿数、緑:採択率、赤:採択された論文数)
国別の論文採択数をみると、日本は3位でした。3位という順位は去年と変わりませんが、今年は中国に抜かれてしまい、中国の成長度合いがうかがえます。


発表内容の内訳
対象アプリケーションとしては、自動運転がもっとも多く、全体の14%を占めていました。技術としては、ディープラーニングの進化の影響で、認識・機械学習で全体の32%を占めていました。

企業展示
企業展示コーナーでは、さまざまなロボットが展示されていました。
中でも、犬のような脚式ロボットは数多く見られました。聞くところによると、脚式の制御ソフトウェアがすでにオープンソースとして公開されているらしく、様々な企業が参入してきたものと思われます。
その他、部品をつかむためのハンドや搬送のための自律移動も数多く展示されておりました。部品をつかんで搬送するといった、付加価値を生まない作業の自動化は産業界からのニーズが大きいようです。これらの自律移動ロボットそのものの論文は少なかったため、研究課題というよりは、すでに実応用のフェーズに来ているものと思われます。

続いて、論文ではないですが、招待講演3件についてです。
①Enbodied visual learning Facebook
講演内容:2.5 visual sound
人間には耳が2つついているため、左右の耳で音量差や到達時間差が存在するため、その音がどの方向から到来しているかが判別でき、また、その音だけを分離して聞くことができます。
2つ以上のマイクを使用すれば、同様のことはできるのですが、それを単一のマイク+画像で行う深層学習モデルの研究です。
学習には、ゴープロとバイノーラルマイク(人間の耳を模したもの)で作成したデータセットを使用します。左右のマイクには、それぞれの音源方向に応じて、微妙に到達時間の違う音が録音されていますが、画像上で見える位置関係とマイクの左右差の関係を学習します。
推論時には、単一のマイクのみのデータと画像の位置関係から、左右のマイクのデータを推測します。左右マイクのデータが正しく推測できれば、従来の信号処理で片方の音だけを分離することができるというものです。
わざわざ単一のマイクからバイノーラル音源を復元しなければいけないシチュエーションがどれほどあるのかは疑問ですが、面白い問題設定だと感じました。昔のビデオカメラやスマホで録画した動画はモノラル音源であることが多いと思うので、そういった動画に対して、聞きたい人の声だけを分離するなどの応用を考えているのでしょうか。

②AI in medicine where are we heading?
講演内容:
・医療領域でもAIやロボットは盛んに研究されており、主に以下の3項目で期待される
1. 高速かつ高精度な画像診断
CT, MRI, 乳がん肺がん脳腫瘍診断など、すでにエキスパートを超えている
カプセル型の胃腸カメラは6時間ぐらいの動画であるため、
工数の無駄、集中力の限界の問題がある⇒AIの診断を活用(75%→99%)
2. 業務効率を改善し、医療ミスを削減する
3. 統計データから個人の健康を向上→スマホにデータを入力すればわかる
所感:
AIを使った画像診断の研究はとても有名ですが、正解率以外に何のメリットがあるかが印象的でした。
・最終判断は人が行っているが、それでも工数削減と精度向上を両立している
・人には集中力の限界があるので、時間削減や診断支援にも十分価値があると感じた
③ImPACT Tough Robotics
講演内容:災害ロボットに求められること
・人のアクセスできない場所での、状況調査・復帰支援
・がれきや雨など、過酷な環境である場合が多い
⇒蛇型のロボットやドローンを使った要求は多い
⇒深層学習を用いた画像のノイズ除去(下図)
所感:
フェーズによって、災害ロボとに求められる能力が異なるというのが印象的で、特に、災害発生直後は、状況調査がもっとも重要だということを初めて知りました。なので、アームやマニピュレータがついた大掛かりなロボットではなく、ドローンや蛇型のがれきの多い場所でも移動可能なロボットが求められるようです。

Okatani, Dual Residual Networks Leveraging the Potential of Paired Operations for Image Restoration, CVPR, 2019
参加レポート②は、音を使った研究テーマのまとめです。図はすべて論文から引用しています。自分用のまとめ的な意味も含むので、興味があれば、論文タイトルでググってみていただけると幸いです。
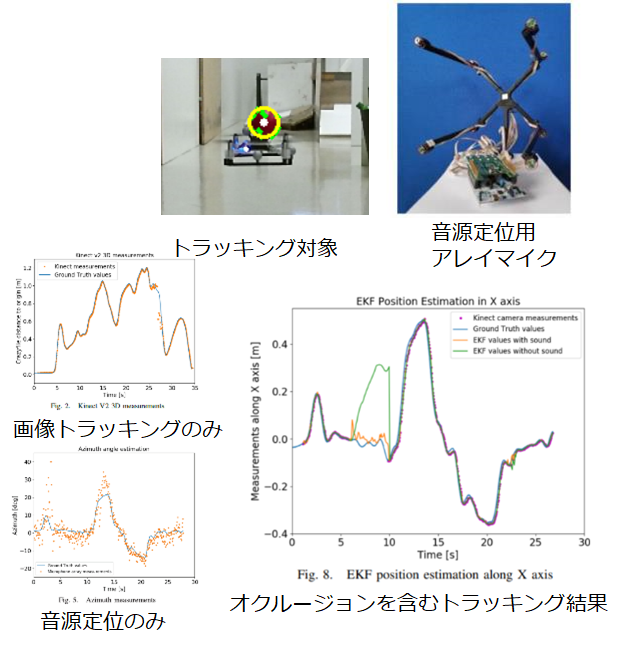
①Cooperative Audio-Visual System for Localizing Small Aerial Robots
目的:画像を使ったトラッキングにおいて、対象物がオクルージョンや画角外にあるときのロバスト性向上
手法:EKFによる画像トラッキングと音源定位とのフュージョン
もう少し、具体的にいうと、画像を使ったトラッキングというのは、画像に映ったドローンを画像認識で追跡するという技術です。当然、ドローンが画角から外れてしまったり、ほかの物体の背後に隠れてしまった場合は追跡できません。
一方、音源定位は、複数のマイクをアレイ状に配置し、対象物の音の到達時間に差が生じることを利用して、音源の到来方向を推定する技術です。画像を使ったトラッキングに比べると、制度は高くありません。
そこで、この研究では、ドローンが画像からトラッキングできない場合に、音源定位を併用することで、安定して追跡ができるようにしたものです。ただし、いつどっちのセンサを信用していいかはわからないため、拡張カルマンフィルタ(EKF)という手法を用いて、どちらのセンサを信用するべきか、重みを算出します。
結果:
・単体では画像を用いたトラッキングの方が明らかに精度は高い
・画像で見えなかったときには、本手法のメリットがある
制約:
・ドローンのような音を発生させる物が対象
・おそらくノイズに弱い
所感:
・ドローンのような比較的小型かつ大きな音を発するものには有効
・人のトラッキングには課題が残る
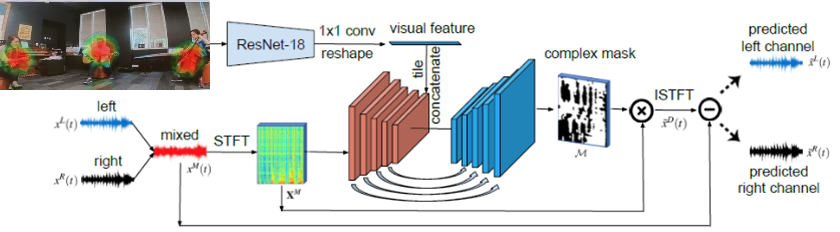
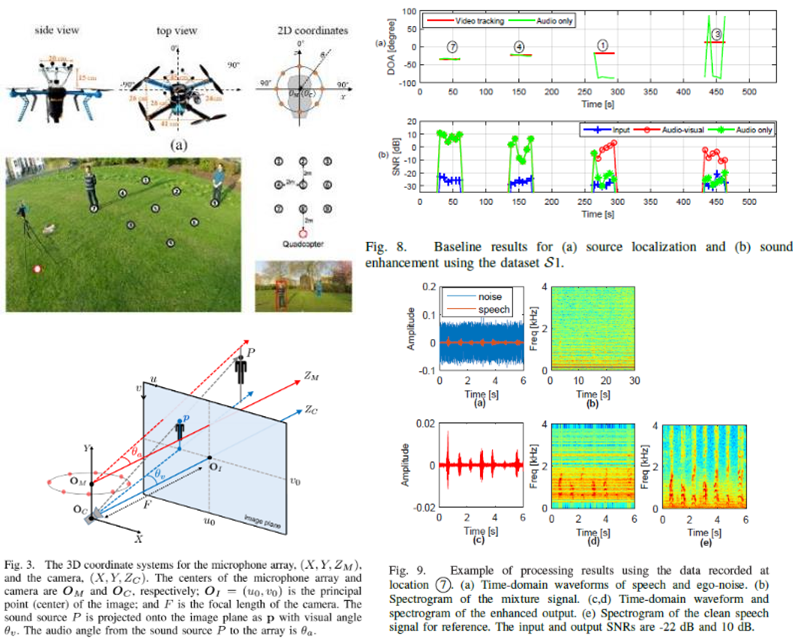
②Audio-visual sensing from a quadcopter: dataset and baselines for source localization and sound enhancement
目的:画像と音を組み合わせたデータセットの提案
手法:
・ドローンにカメラ、アレイマイクを取り付け、最大2名を含むデータセット作成
・既存の音源定位・分離手法に画像トラッキングを組み合わせた手法で評価
こちらは、①の論文と似ていますが、どちらかというと音源分離に重きを置いています。
従来、特定の音だけを分離する場合、以下の図上のアプローチをとることが多いです。つまり、最初に音源の方向を定位したのち、その方向の音だけを分離します。
しかし、①の研究でもありましたが、外部からの雑音などの影響により、音源定位の性能が低くなってしまうことがあります。(図右上の緑線)
そこで、この研究では①とは逆に、音源定位は画像を使ったトラッキングを行うことで、以降の音源分離の性能が向上すると主張しています。
(この論文のメインは、そういったデータセットを作ったというところにもあるので、手法自体はあくまでベースラインかもしれませんが)
結果:性能の悪い音源定位の代わりに、画像トラッキングを用いることで、音源分離の性能を向上
所感:対象が画角に写っている必要がある。EKFのようなフュージョンが必要

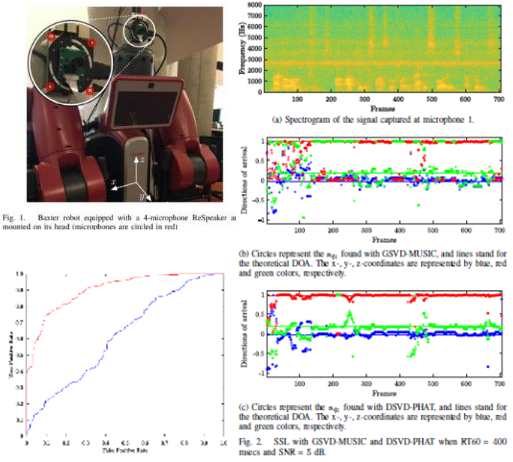
③Fast and Robust 3-D Sound Source Localization with DSVD-PHAT
目的:GSVD-MUSICに比べ、計算コストの低い音源定位アルゴリズムの開発
手法:MUSIC法は相関行列を固有値分解するのに対し、サブトラクションを行うので、計算量を低く抑えられる
この手法は数学的に理解が難しいので省略しますが、比較に使われているGSVD-MUSICは、複数チャンネルの音データの行列の掛け算を計算するので、計算コストが非常に大きいのに対し、引き算を使っているので、計算量が少なく済むようです。

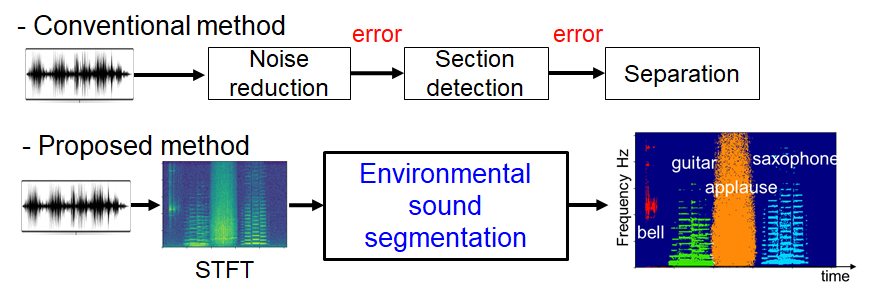
④Environmental sound segmentation
目的:
・②に書きましたが、従来は音源定位・音源分離など、それぞれの手法が順に実行されるので、上段の結果に誤差があると、以降の結果もすべて悪くなります。これは、各ブロックが全体最適でなく、それぞれが局所最適されているために起こっているため、図下のような深層学習ネットワークで全体最適化を図ります。
・また、従来研究は音声認識を目的としたスピーチ分離など、クラス数の少ない研究が多いです。しかし、より汎用的なロボットであるためには、シーンによっては鳥の声を聞き分けたりと、他の環境音も認識する必要があります。したがって、そのための汎用アルゴリズムとして、あらゆる環境音を聞き分けることが可能な深層学習アプローチを提案しました。
今回は、ポイントクラウド、セグメンテーションに関連した研究です。こちらも、図はすべて論文から引用しています。
近年では、画像のセマンティックセグメンテーションそのものの研究は減ってきていて、ポイントクラウドのセマンティックセグメンテーションの研究が増えてきているようです。画像と比較して、天気や昼夜の影響を受けないので、自動運転など、信頼性が重要なアプリケーションへの応用が期待されます。
①RangeNet++: Fast and Accurate LiDAR Semantic Segmentation
目的:自動運転のためのLidar only セグメンテーション
手法:
・Lidarのポイントクラウドのみでのセグメンテーション。
・ポイントクラウドを画像化し、CNNでセグメンテーション
所感:天候に左右されないので、メリットはあると感じた
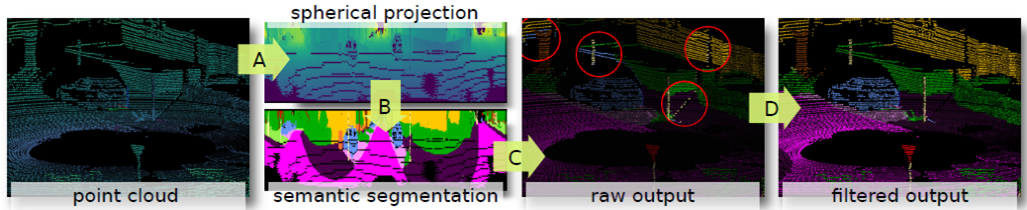
②PanopticFusion: Online Volumetric Semantic Mapping at the Level of Stuff and Things
目的:3DデータのPanoptic segmentation
背景:3Dの畳み込みは複雑で重い
手法:PSPNetとMask R-CNNを用いて2Dセグメンテーションを行い、depth画像を使って3D再構成


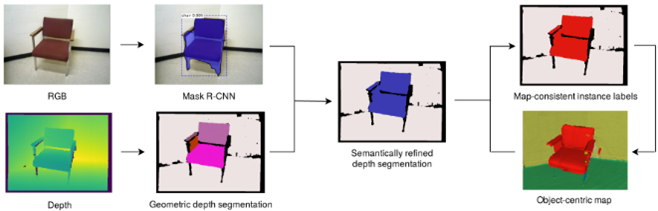
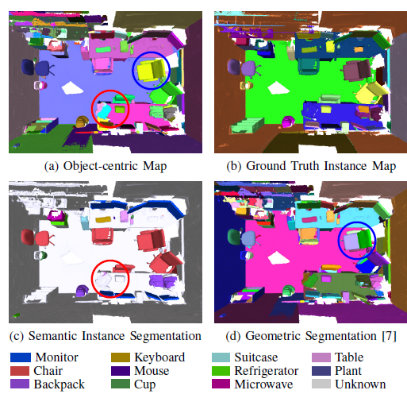
③Volumetric Instance-Aware Semantic Mapping and 3D Object Discovery
目的:3DデータのInstance segmentation
背景:3Dインスタンスセグメンテーションができれば、把持などに応用できる
手法:
・RGBDデータを使って2Dセグメンテーションをし, 3D reconstruction
・2DセグメンテーションにはMask R-CNNを利用
所感:
・他の論文も含め、既存ネットワークを使った応用研究が多い
・認識系研究(pose estimation等も含む)の多くは、自動運転、マニピュレーションを目的としているものが多かった
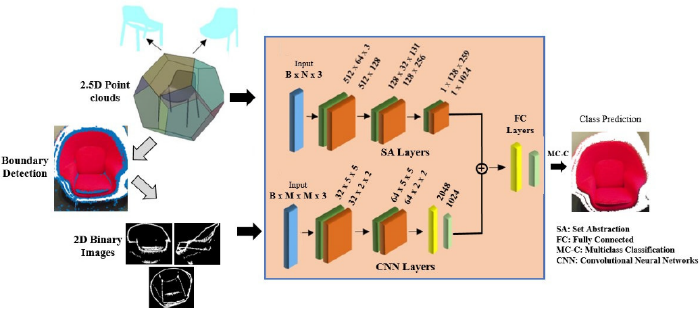
④EPN: Edge-Aware PointNet for Object Recognition from Multi-View 2.5D Point Clouds
目的:PointNetの改良
背景:ポイント数が多すぎてDNNかけられないので、どうやって効率的にポイント特徴を抽出するか?
手法:
・PointNet++にエッジ検出用の2D CNNブランチを追加
・Egde-awareにすることで、PointNet++を上回る性能
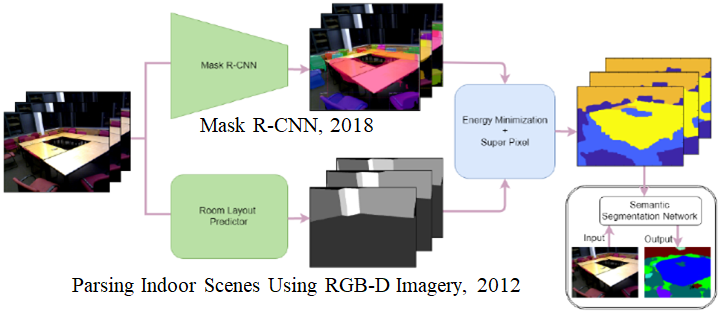
⑤Automatic Annotation for Semantic Segmentation in Indoor Scenes
目的:動画に対し、セマンティックセグメンテーション用アノテーション自動化
手法:Pre-trained Mask R-CNNと部屋のレイアウト予測ネットワークなど、複数の既存ネットワークを組み合わせる
所感:Mask R-CNN自体の性能にかなり影響を受けるものと思われるので、結局のところMask R-CNNの学習が必要に思うが、新しいアプローチ