本記事では、複数話者の音声認識における音声認識の難しさについて簡単に述べた後、そのようなユースケースでの必須技術であるSpeaker diarizationの概要をまとめます。
複数話者の音声認識の難しさ
以前の記事で、End-to-end音声認識モデルについてまとめましたが、これらの音声認識モデルは、基本的には左図のようなクリーンな音声を対象としています。
しかし、よりユーザの使い勝手向上のためには、右図のような複数話者が一つのマイクを使用するようなケースに対応する必要があります。
このような環境では、複数話者の音声や周囲の雑音が混入してしまうため、上記のようなクリーンな音声を想定している音声認識モデルをそのまま適用すると大幅な性能劣化が生じることが知られています。

複数話者の音声認識を行うための一般的なパイプライン
このような環境で正しく音声認識を行うためには、音声認識モデルに音声を入力する前に、話者ごとに音声信号を分離する必要があります。
以下の右図に示すのは、その一例であり、Speaker diarization、音源分離、音声認識モデルから構成されています。簡単に各モジュールの役割について述べます。

①Speaker diarization
複数話者の音声の混合信号を入力とし、「誰が○○秒~○○秒まで話した」という情報を出力します。発話区間検出(Voice Activity Detection, VAD)の多クラス版ということになります。
②音源分離
Speaker diarizationで「誰が○○秒~○○秒まで話した」という情報が得られれば、話者ごとに別々に音声認識を行うことが可能になりますが、実際のシーンでは複数話者が同時に話していることあります。
そのようなオーバーラップした発話を正確に認識するために、音源分離を行います。
音源分離については、少し古いですが、以下も参照いただければと思います。
③音声認識
話者ごとに分離された音声信号が音声認識モデルに入力され、結果として話者ごとに音声認識結果が得られます。
Speaker diarizationとは?
ここでは、上記のパイプラインにおけるSpeaker diarizationについて、もう少し詳しく述べます。
繰り返しになりますが、Speaker diarizationとは、複数話者の混合信号から、「誰が○○秒~○○秒まで話した」という情報を出力します。より具体的にいうと、下図のように、各時間フレームごとに、アクティブな話者IDを出力します。

従来のSpeaker diarization
音声認識モデルの歴史とよく似ていますが、従来は以下に示す複数のモジュールにより、Speaker diarizationは実現されていました。
①発話区間検出(Voice Activity Detection, VAD)
まず、話者IDによらず、発話区間のみを抽出します。
発話区間検出としては、エネルギベースの手法,統計モデルを用いた手法や深層学習ベースの方法も提案されています。
②Speaker embedding
VADにより検出された発話区間の信号に対し、各時間フレームごとにi-vectorやx-vectorなどのspeaker embeddingを計算します。
speaker embeddingは話者ごとの声質の特徴をとらえたものとみなすことができ、声を使った本人認証や話者識別にも使用されています。
③クラスタリング
Speaker embeddingは話者の声質特徴とみなすことができるので、それらをクラスタリングすることで、話者ごとにspeaker embeddingを分離することができます。
これらの処理は、各時間フレーム事に行われているので、Speaker diarizationの目的である、「誰が○○秒~○○秒まで話した」という情報得ることができます。

しかし、このようなクラスタリングアプローチには、一つ大きな問題があります。
③でクラスタリングアプローチを採用しているため、必ずどれか1人の話者IDにしか分類されないことです。
すなわち、複数話者がオーバーラップして話していた場合、必ずどちらか片方の話者しかアクティブになりません。
End-to-End Neural Diarization (EEND)
そこで、近年、3つのモジュールから構成されていたSpeaker diarizationを一つのニューラルネットワークで実現する、End-to-End Neural Diarization (EEND)が提案されています。

EENDアプローチでは、マルチクラスアプローチではなく、マルチラベルアプローチを採用することで、複数話者のオーバーラップにも対応することができます。
以下の図にマルチクラスとマルチラベルの違いを示しています。

・マルチクラス
マルチクラスアプローチでは、最終層にSoftmax関数を採用しており、必ずどれか1つのクラスが選択されます。
そのため、オーバーラップした発話には対応することができませんが、ImageNetのような、画像のクラス分類(dog or cat or horse) のように、重複することがないタスクに適しています。
・マルチラベル
一方、マルチラベルアプローチでは、最終層にSigmoid関数を使用することで、複数のクラスが同時にアクティブになることできます。
Speaker diarizationのほかに、音響イベント検出にも適しています。
クラスタリングアプローチとEENDの比較
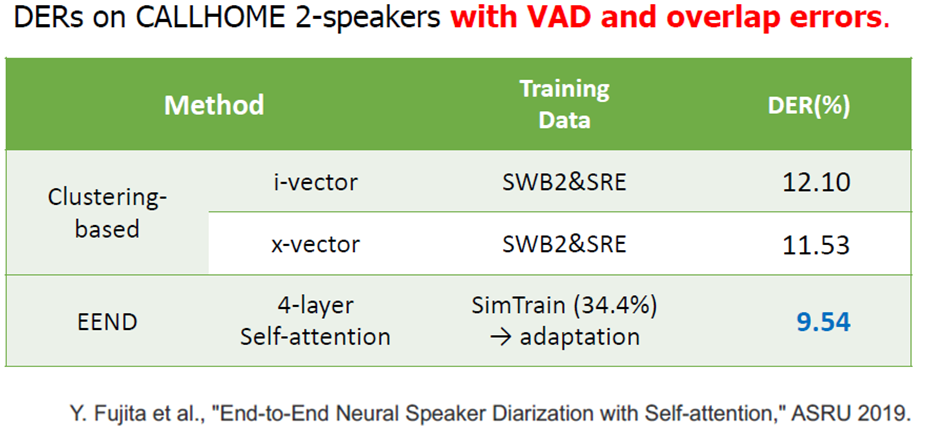
以下は、2019年の論文で提供されている実験結果を引用しています。
上記のように、EENDはオーバーラップに対応することができるため、DER (Diarization Error Rate) という指標で、よりエラーが小さくなっていることが示されています。
まとめ
本記事では、複数話者の音声認識の概要とその必須モジュールであるSpeaker diarizationについて述べました。
本記事では、オーバーラップに対応できるという利点に焦点を当てましたが、話者数のカウントが難しいというような課題も存在します。
もし興味がありましたら、さらに調べてみていただければと思います。