手話認識の必要性
以下の図は、深層学習を活用した健聴者と手話話者とのコミュニケーション例を示しています。
上図に示すように、健聴者→手話話者には、音声認識モデルを使用することができます。
深層学習と学習データの拡充にともない、近年は非常に高い精度で音声を書き起こすことができますので、下図に示すように、いくつかのアプリもリリースされています。


しかし、反対に手話話者が健聴者に何かを発信する場合、依然として筆談などの方法に頼らざるを得ず、リアルタイムでスムーズにコミュニケーションをとるのは非常に難しいのが現状です。

したがって、手話話者と健聴者のコミュニケーションをサポートするためには、下の図のように手話認識技術が必要です。
また、上段の音声認識でさえ、手話に比べると理解しづらい場合があるので、できればテキストではなく手話を生成することが望ましいです。本記事では、手話認識に焦点を当てるので、手話生成については割愛します。

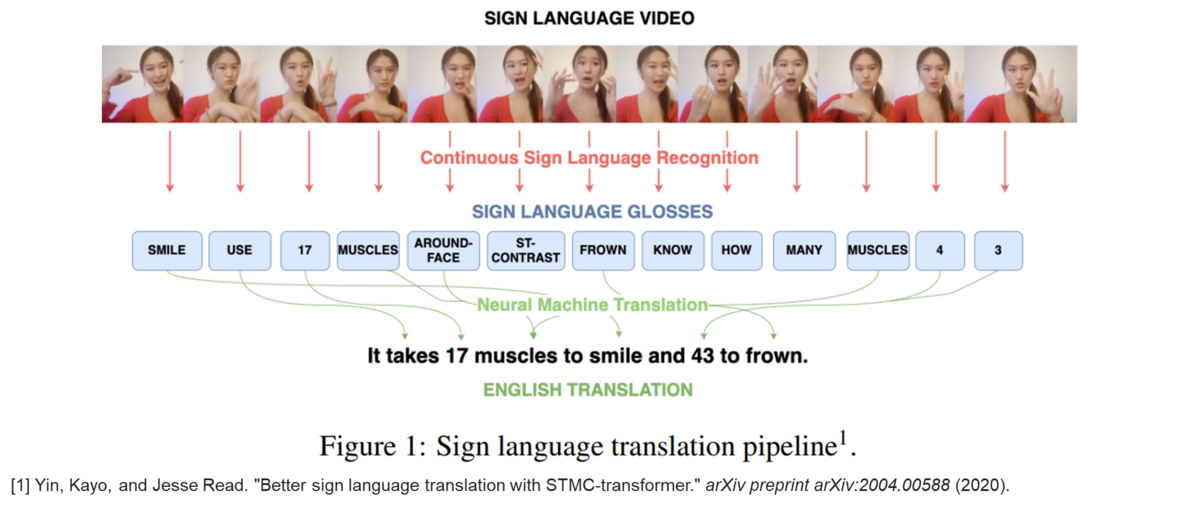
手話認識の概要
以下の図は、手話認識の一般的なパイプラインを示しています。
一般に手話はGlossと呼ばれる、単語のような単位から構成されており、Glossを複数組み合わせることでセンテンスを表します。
したがって、健聴者が理解しやすいように、Glossシーケンスを一般的なテキストシーケンスに翻訳する必要があります。
ここでは、手話からGlossシーケンスへの変換を手話認識、Glossシーケンスからテキストシーケンスへの変換を手話翻訳と呼びます。
Yin, Kayo, and Jesse Read. "Better sign language translation with STMC-transformer." arXiv preprint arXiv:2004.00588 (2020).
カスケード手話翻訳からEnd-to-end手話翻訳へ
過去に、音声認識やSpeaker diarizationと同じく、手話翻訳についても、近年、ニューラルネットワークを用いたEnd-to-end手話翻訳が提案されています。

2] Necati Cihan Camgoz et al. “Neural sign language translation”. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2018, pp. 7784–7793
しかし、以下の表に示す通り、音声認識と異なり手話翻訳にはデータセットが圧倒的に少ないという大きな課題があります。
データセットが少ないため、結果として認識性能も悪い傾向があり、実用化を妨げています。
今後のアプローチとしては、放送局やYoutubeの手話データ等を用いた学習データの拡充や大規模言語モデル、音声モデル等の活用による手話翻訳モデルの性能向上が考えられます。

[2] Necati Cihan Camgoz et al. “Neural sign language translation”. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2018, pp. 7784–7793
[3] Camgoz, Necati Cihan, et al. "Sign language transformers: Joint end-to-end sign language recognition and translation." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020.