以前の記事で、アレクサにも使われていると思われる、音響イベント検出というディープラーニング技術について解説しました。
当時は、アレクサの中身を知っているわけではなかったので、具体的にどのようなアルゴリズムが使われているかまではわかりませんでしたが、2019年6月に開催された、「Amazon Re: MARS」というワークショップの講演動画がyoutubeに上がっていました。
今回は、リンクの動画を参考に、調査した内容を以下にまとめます。図は動画から引用させていただきました。
こちらの動画では、Alexa Guardに使われている音響イベント検出についての説明されています。
Alexa Guardとは
アマゾンエコーに搭載されているアプリケーションの名前で、ユーザーが外出中に、家の中の見守りを行ってくれます。
具体的には、ガラス破損音や火災報知機のアラームなどの異常音を検知し、スマホにお知らせしてくれたりします。検出された音データは10秒間録音されており、スマホから実際に聞くことでき、実際に何が起こったのか、自分の耳で確かめることができます。
この機能を実現するために使われている技術が音響イベント検出です。ここから、音響イベント検出とは何か、どういったAI技術なのか説明していきます。
音響イベント検出とは
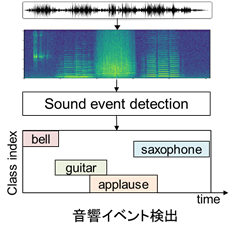
音響イベント検出とは、環境音認識のためのタスクで、以下の図のように、音データの中から特定の音響イベントの発生区間を検出するというものです。
図の下側のように、「○○秒~○○秒にギターの音が鳴っている」といったことが、自動で分かるようになります。
近年はディープラーニングを用いた手法が主流となっており、中でも、CNNとRNNを組み合わせたCRNNというネットワークが高い性能を示すことが報告されています。CRNNの詳細は以下のリンクを参照ください。
Alexa Guardのシステム構成
では、Alexa Guardはどのような構成になっているでしょうか。全体の構成は以下の図の通りで、大きく3つの構成からなっております。

①エッジデバイス(アマゾンエコー)
常時音データを監視し、疑わしい音響イベントの検知を行います。エッジデバイスは、最低限のメモリや計算能力しか持っていないので、計算負荷の高い深層学習は使うことができません。またメモリ節約のため、検知されたイベント区間のみクラウドに送信し、それ以外の音データは破棄します。
②クラウドコンピュータ
エッジデバイスで検出されたイベント区間の音データを受信します。ガラス破損音のような重大な事象を誤検知することは好ましくないので、音響イベント検出の精度は高い必要がありますが、エッジデバイスに高精度な計算負荷の高い深層学習モデルは実装できません。そこで、クラウド上で、再度、高精度な音響イベント検出を実行し、エッジデバイスで検出されたイベントが正しいかどうかを判定します。
クラウドコンピュータにおいても、音響イベントが検出された場合、ユーザのスマートフォンに通知されます。
③ユーザのスマートフォン
検出された音響イベントとともに、録音された音データを聞くことができます。ユーザの耳で実際に何が起こったかを最終判断します。
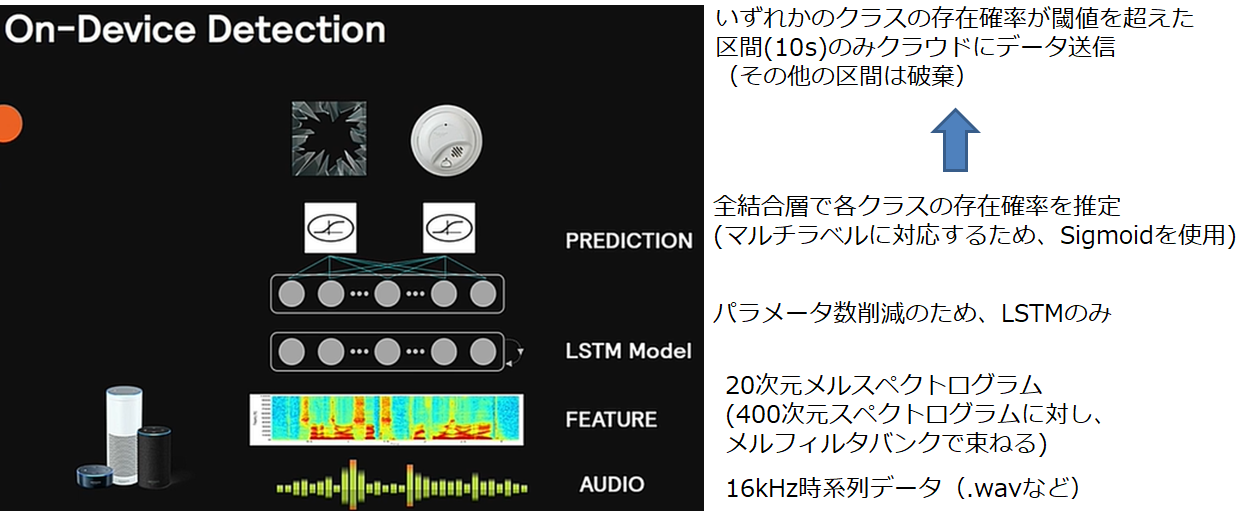
エッジデバイスの深層学習モデル
次に、エッジ側デバイスのモデルについて詳細に説明します。
上で説明したように、エッジデバイスはメモリや処理能力に限りがあります。
したがって、特徴量の次元を最小限に削減、イベント以外の区間のデータ破棄、小さいネットワークを使用するなど、計算コスト削減のための工夫がなされております。
具体的には、以下の図のようになっています。
まず、特徴量の次元を極力下げるため、16kHzで音データは収録されています。フーリエ変換を行うとその半分の周波数までしか分析できないことを考えると、これ以上サンプリングレートを下げることは難しいかもしれません。
特徴量としては、16kHzの時系列データをそのまま使うのではなく、20次元のメルスペクトログラムに変換します。
深層学習モデルにはLSTMを用いています。CNNと組み合わせたほうが高性能なモデルになると思いますが、パラメータ数の節約のため、LSTMのみのネットワークにしているようです。
最終層は、活性化関数にSigmoidを用いた全結合層を用いています。
クラウドコンピュータの深層学習モデル
次に、クラウドコンピュータのモデルについて説明します。
エッジデバイスとは異なり、クラウドコンピュータには潤沢なメモリと計算資源があります。ガラス破損音のような重大事項を聞き逃すわけにはいかないので、計算負荷が高くても、できるだけ高精度なネットワークを実装する必要があります。
具体的には、以下の図の通りで、エッジ側モデルと異なり、深層学習モデルには、より高精度なモデルであるCRNNを使用していました。

データセット
次に、学習に使用したデータセットについてです。高精度な音響イベント検出を行うためには、高品質かつ大量のデータが必要です。
アマゾンでは、100種類以上のガラス破損音を作成し、あらゆる日常音にミックスすることで、データセットを作成したようです。

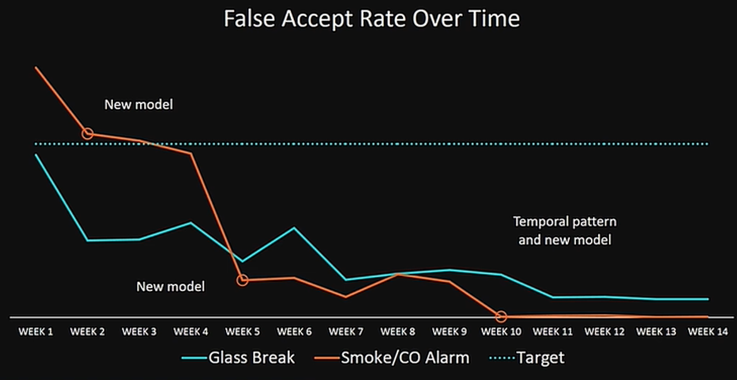
Active learningを用いた継続的な学習
上で述べた方法で、ある程度のデータセットは作成可能ですが、それでも学習データに含まれていない音が現実世界には存在します。
そこで、Active learning という手法を使って、サービスリリース後も効率的に学習データを増やし続け、深層学習モデルの性能を向上させているそうです。
その結果が以下の図です。サービス開始後10週間後にはエラー率がほぼ0にまで削減されていることが分かります。
まとめ
Alexa Guardに使用されている音響イベント検出について、Amazon Re: MARSのプレゼン動画をもとに調査した。
結果として、以下のことがわかった。
・2クラスしか対応していない状態でリリース
・エッジデバイスのリソース制約のため、
エッジ・クラウドのハイブリッド構成で音響イベント検出を行っている
・初期データには、ガラス破損音や日常のバックグラウンドノイズを収録
・Active learningを用いて、リリース後も継続的に学習
(ラベリングはユーザに行わせている?)
また、アマゾンエコーには防犯機能だけでなく、さまざまな技術が搭載され続けています。以下の記事では、感情認識に関する技術の解説を行っていますので、よければそちらもご覧ください。
ご意見、ご質問、調べてほしいことなどあれば、コメントください。
励みになりますので、お気に入り登録もよろしくお願いいたします!