今回はディープラーニングを使った、ロボットの自己位置認識技術について考えます。個人的な見解なので、これがスタンダードではないことをご了承ください。
自己位置認識に使われるセンサー
以下の図は、ロボットの自己位置認識によく使われるセンサの一例です。
例えば、IMUでは、ロボットの加速度や角加速度がわかるので、ロボット自身の移動距離や姿勢を推定することができます。
ステレオカメラは、人間の目のように2つのカメラの画像から、3D Lidarは、照射したレーザー光の反射時間から、それぞれ障害物や壁との距離を測定することができます。測定した外部環境との距離データとあらかじめ持っているマップデータをマッチングすることで、自己位置を推定することができます。
一番右のUWBは、インフラが必要になってしまいますが、ロボット自身にタグを、周囲の環境に電波の発信源を最低3つ以上設置しておくことで、三角測量の原理でロボットの位置を推定することができます。
しかし、これらのセンサの問題は、求められる自己位置推定精度が高くなればなるほど高価になります。3D Lidarは自動運転にも使われていますが、現状ネットで購入しようとすると数十万はします。

人間のようにファジーに推定できないか?
さて、ここで、人間がどのように自己位置を推定しているかを考えてみます。別の記事でも書きましたが、人間は時間細胞やエピソード細胞、グリッド細胞など、ロボットに似た仕組みで自己位置を推定していることが有力な仮説(パスインテグレータ仮説)となっています。
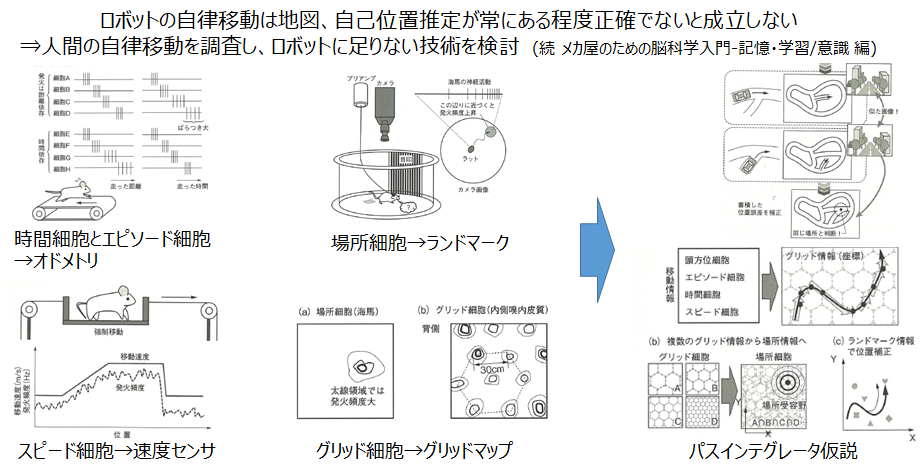
メカ屋のための脳科学入門-脳をリバースエンジニアリングする
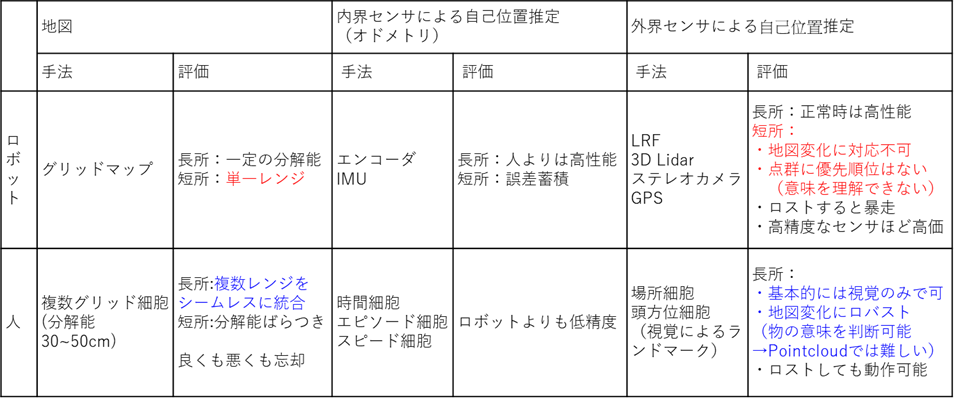
ここで、人間とロボットの違いを以下の表で比較してみます。
ロボットも人間も自分の歩いた距離や時間を推定することができますが、明らかにロボットの方が高精度に推定できます。しかし、人間にしてみれば、数センチ単位の自己位置推定をやる必要もなく、迷わないことの方が重要です。
決定的に違うのは、人間は仮に片目を瞑った状態(1枚の画像の情報)でも、自分の位置を把握することができます。ロボットでいえば、単眼のカメラは3D Lidarやステレオカメラに比べ、かなり安いコストで購入することができます。
そこで、今回は、単眼の画像データを用いた自己位置推定に関連しそうな分野について調べてみます。
関連分野
調べた限りでは、以下の2つが近い分野かなと考えました。
① Place recognition
入力画像から、事前に取得したデータベースからもっとも近い画像を推定(分類タスク)
→分解能はもとのデータベースに制限されるため、必要な分解能以上のデータが必要
→各場所は独立なものとして扱われるため、位置関係は学習できない(入力画像とデータベース画像のマッチングに相当)

② Camera pose regression
入力画像から、x, y, z, roll, pitch, yawを回帰するタスク
→分解能はもとのデータセットによらない(タスクとしては)
→入力画像の位置を学習することに相当
→連続値であるので、オドメトリやGPSとの相性がいい
おそらく、人間が行っているのは、①のplace recognitionだと思いますが、ロボットには座標値として自己位置を与えてやる必要があるので、今回は②のpose regressionを調べます。
関連研究(pose regression)
以下に代表的な関連研究を示します。基本的には2015年に発表されたPosenetという手法を改良したものが主流のようです。古いものから順に簡単に説明します。
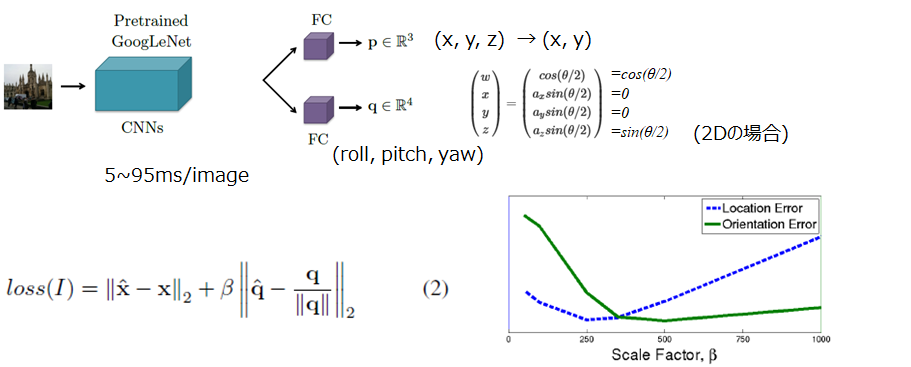
- Posenet [Kendall+ 2015]
RGB画像にCNNを適用し、6-DOB姿勢推定を行う。 Positionとorientationで損失に重みづけを行う。orientationは、クォータニオンを予測するため不連続点がない。
- Hourglass Networks[Melekhov+ 2017]
hourglassとは、砂時計のことを意味します。encoder-decoder構造のような構造を持っています。基本的には、Posenetのネットワークを改良した研究です。

- LSTMs for structured feature correlation[Walch+ 2017]
CNN層の後にLSTMを追加(複数画像の時系列contextではなく、特徴マップのx,y方向contextを学習)。こちらも、Posenetのネットワークを改良した研究です。
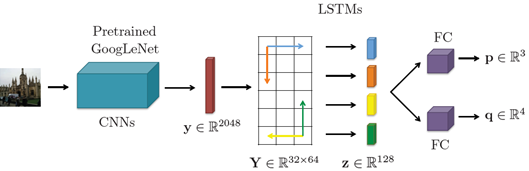
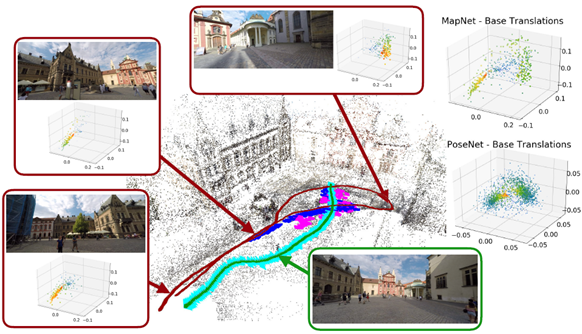
- MapNet [Brahmbhatt+ 2018]
現状のstate-of-the-art手法です。Posenetは入力画像と出力としての座標値をセットが、学習データとして必要でしたが、Mapnetでは、2枚のペア画像に対し、IMUなどのセンサから推定した移動距離(相対位置)を教師として、学習することができるよう改良されています。
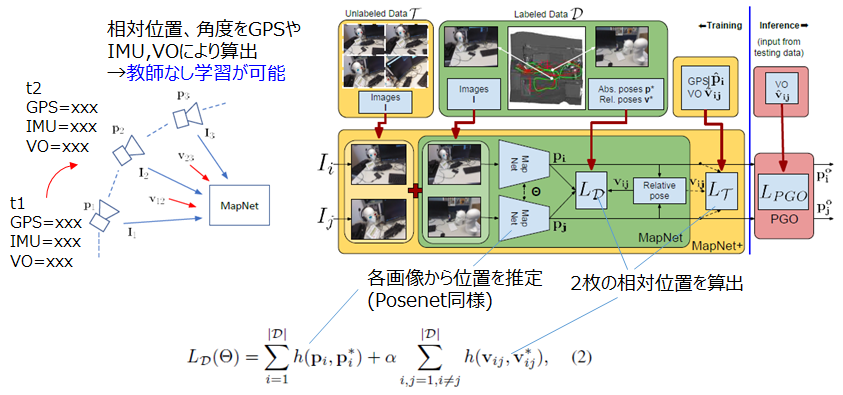
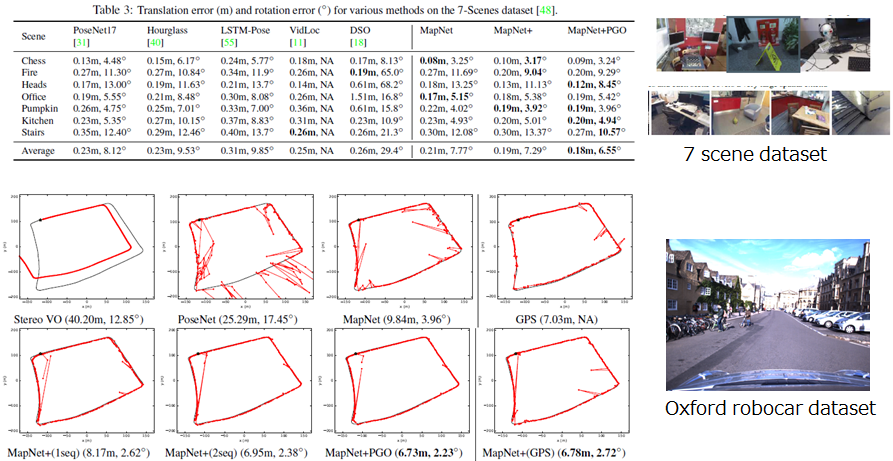
実験結果(Mapnet論文内のデータ)
以下が、各手法の比較結果です。Mapnetがもっとも高い性能を示していることが分かります。
参考文献
Kendall, Alex, Matthew Grimes, and Roberto Cipolla. "Posenet: A convolutional network for real-time 6-dof camera relocalization." Proceedings of the IEEE international conference on computer vision. 2015.
Melekhov, Iaroslav, et al. "Image-based localization using hourglass networks." Proceedings of the IEEE International Conference on Computer Vision. 2017.
Walch, Florian, et al. "Image-based localization using lstms for structured feature correlation." Proceedings of the IEEE International Conference on Computer Vision. 2017.Brahmbhatt, Samarth, et al. "Geometry-aware learning of maps for camera localization." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.
ご意見、ご質問、調べてほしいことなどあれば、コメントください。
励みになりますので、お気に入り登録もよろしくお願いいたします!