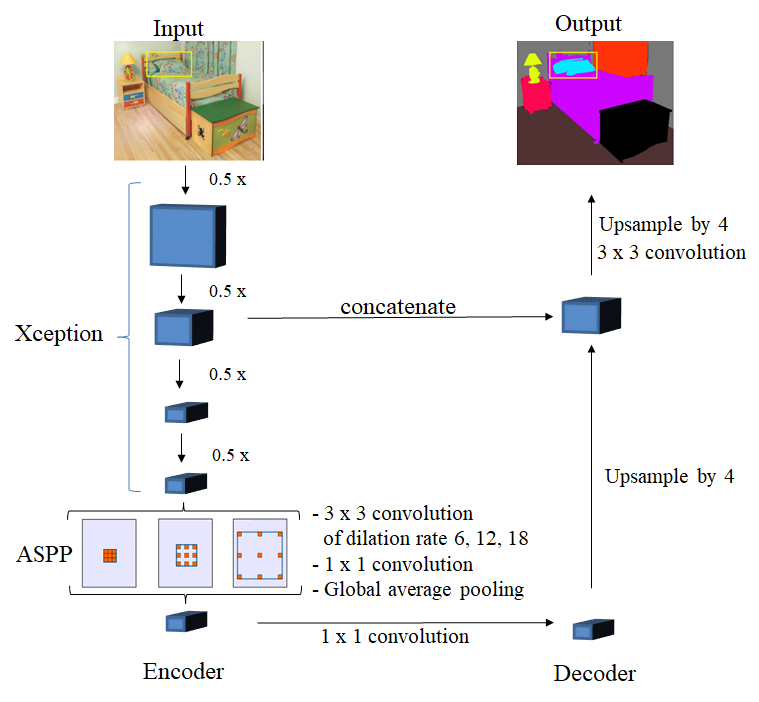
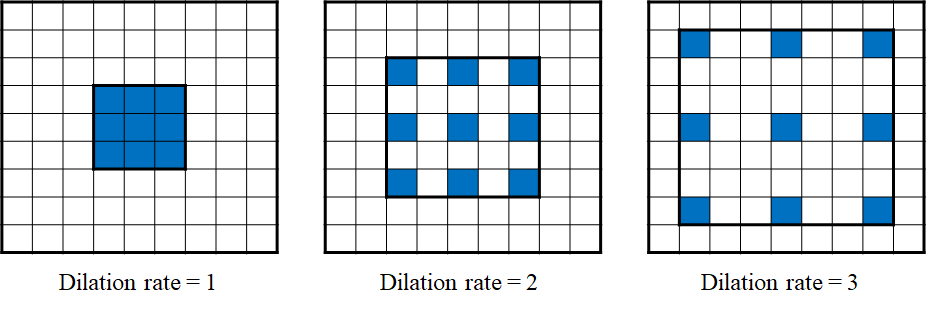
[1] L.-C. Chen, Y. Zhu, G. Papandreou, F. Schroff, and H. Adam, “Encoder-decoder with atrous separable convolution for semantic image segmentation”, The European Conference on Computer Vision (ECCV), 2018, pp. 801-818
[2] F. Chollet, “Xception: Deep learning with depthwise separable convolutions”, The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 1251-1258.
[3] F. Yu and V. Koltun, “Multi-scale context aggregation by dilated convolutions”, arXiv:1511.07122, 2015.
[4] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and Alan L. Yuille, “DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs”, IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 40, Issue 4, pp. 834-848, April 2017.
[5] L.-C. Chen, G. Papandreou, F. Schroff, and H. Adam, “Rethinking atrous convolution for semantic image segmentation”, arXiv:1706.05587, 2017.