今回は、画像のセマンティックセグメンテーション手法の1つであるU-Netを用いた歌声分離を紹介します。参考文献は以下の2つの論文です。
Andreas Jansson, Eric J. Humphrey, Nicola Montecchio, Rachel Bittner, Aparna Kumar, Tillman Weyde, Singing Voice Separation with Deep U-Net Convolutional Networks, Proceedings of the 18th International Society for Music Information Retrieval Conference (ISMIR), 2017.
Duyeon Kim, Jaehoon Oh. “vocal separation from songs using deep convolutional encoder-decoder networks, GCT634 , KAIST, Korea, 2018.
全体概要
以下の図は、全体概要を示しています。まず、歌声、伴奏が混ざった音源に対し、短時間フーリエ変換を行います。短時間フーリエ変換では、複素数の結果が得られるので、振幅、位相スペクトルに分解します。そのうち、振幅スペクトルを画像と見立てて、セマンティックセグメンテーション手法の1つであるU-Netに適用します。
U-Netでは、歌声と伴奏を分離するようなマスク画像を予測します。
しかし、得られた歌声のみの振幅スペクトルだけでは、時系列信号を復元することができません。そこで、混合音のSTFTから得られた位相スペクトルを用いることで、歌声のみの時系列波形を復元することができます。厳密には、混合音の位相スペクトルは、歌声のみの位相スペクトルとは異なるのですが、聴感的にはそれなりの音源が分離できます。

短時間フーリエ変換の補足
なぜ、位相情報が必要になるか、以下の図で捕捉します。
別の記事でも説明しましたが、フーリエ変換を行うと各周波数成分に対し、複素数の結果が得られます。複素数平面において、絶対値が振幅を示し、実数軸との角度が位相を表します。短時間フーリエ変換の場合は、短い窓に区切ってフーリエ変換を行うので、各時間窓・周波数成分ごとに、複素数が得られます。
ここで、U-Netには複素数を入力することができないので、振幅スペクトルに変換する必要があります。しかし、時系列波形を復元するためには、位相情報がないと逆フーリエ変換ができません。U-Netに入力する際に、位相情報は捨ててしまったので、仕方なく混合音の位相スペクトルを使っています。

U-Net
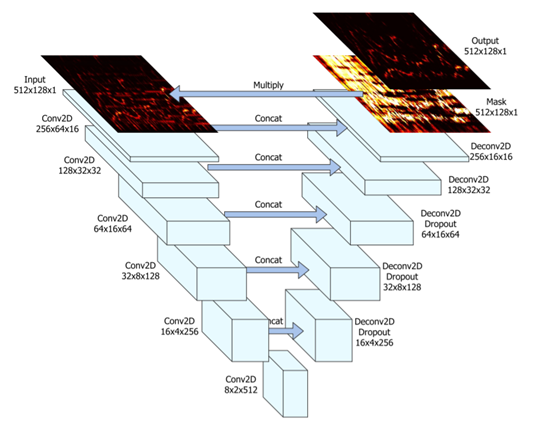
では、実際に学習が行われるU-Netについて、詳しく説明します。U-Netはエンコーダデコーダ構造をとっており、各層の間にスキップ結合をもつことで、高解像度なセグメンテーション画像を予測することを狙ったネットワークです。
画像のセマンティックセグメンテーションとの違いは、歌声の振幅スペクトルを直接予測するのではなく、入力画像と掛け算することによって、歌声のみを取り出すマスク画像を予測する点が異なります。
データセット
参考文献では、Spotifyが研究を行っていることもあり、豊富な音楽データがあるようです。
一般の人が入手可能な音楽データは以下のデータセットが公開されているようです。

まとめ
肝心の結果ですが、私は実装していないので、以下のリンクを参照してみてください。厳密には位相スペクトルは正しくないものを用いていますが、かなり高精度な歌声分離が実現できています。
ただ、この研究もSpotifyが行っていたように、こう言った研究はgoogle, amazonなど、データを持っている企業が非常に強いなという印象です。
U-Netは、もともと自動運転等に使われる画像のセマンティックセグメンテーションというタスクのために提案された手法です。画像のセマンティックセグメンテーションについても、記事を書いていますので、よければそちらもご覧ください。
参考文献
ご意見、ご質問、調べてほしいことなどあれば、コメントください。
励みになりますので、お気に入り登録もよろしくお願いいたします!