音声に関連した研究は電話品質向上がルーツ
音に関連した研究は、電話の品質向上の歴史とともに進化してきました。そうした背景からか、音に関連した研究は、NTTの研究所がとても強い印象があります。
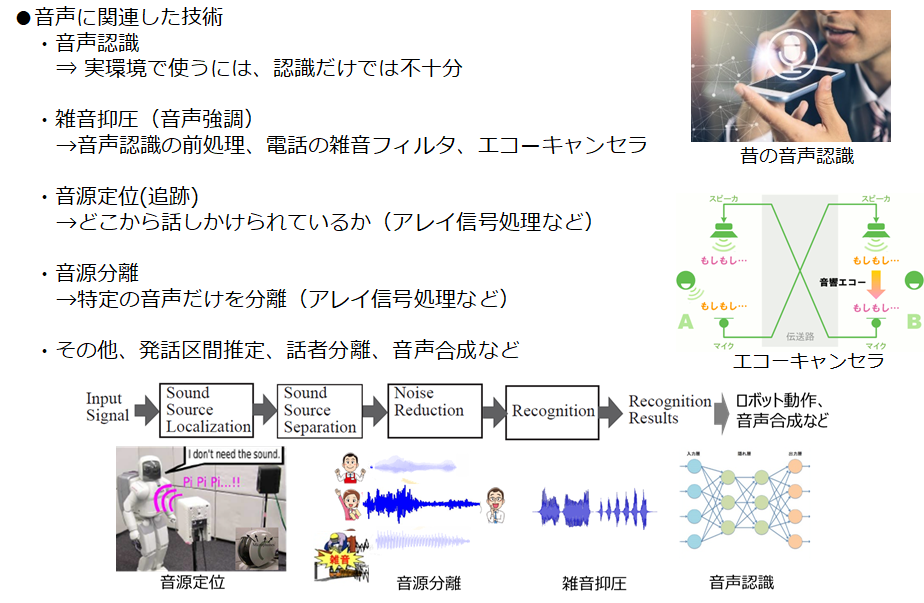
近年のAIブームのおかげで当たり前の技術となっている音声認識ですが、それ以外にもたくさんあります。昔は携帯に近づいて話しかけないとほとんど聞き取ってもらえなかったように、雑音抑圧やエコーキャンセラなど、信号処理の研究テーマが盛んに行われてきました。
電話からロボットへの適応
それまでは、電話品質の向上を主な目的としてきましたが、2000年頃から、ロボットへの適用が研究され始めました。
人間の場合、雑音の多い環境でも、無意識に聞きたい音だけを聞き分けることができてしまうのですが、機械にそれをやらせるのは簡単ではありません。
以下の図は、異なる話し声を1人、2人、8人、16人と増やしていったときの音声波形です。ご覧の通り、話者数が増えれば増えるほど、ランダムな波形に近づいていっております。
いかに、混ざった音声波形から、聞きたい音だけを分離することが難しいかがわかるかと思います。

なぜ人間は音の方向を聞き分けられるのか
そもそもなぜ人間は音の方向を特定したり、聞き分けられるのか。
その理由は、音圧や到達時間に左右差があり、その情報を脳内で処理しているためです。

このように、複数の音源が存在するような環境で、聞きたい音だけを聞き分けることをカクテルパーティー効果と呼びますが、ロボットに実装するには、以下の4つの機能に分解することができます。
・音源定位:音源の方向を特定
・音源分離:特定方向の音源を分離
・雑音抑圧:分離しきれなかった雑音のフィルタリング
・音声認識:処理によってクリーンになった音声の認識

これらの手法はアレイ信号処理をベースにしており、数学的に非常に難解なので、個々では割愛しますが、詳細は以下の教科書に書かれています。唯一の日本語の教科書なので、興味がある方は参考にしてみてください。

深層学習を用いた音源分離
ここまで、アレイ信号処理をベースにした手法について述べてきましたが、近年は、深層学習ベースの手法が多数提案されています。信号処理ベースの手法に比べて、大量の学習データが必要・計算量が大きいといったデメリットはあるものの、大きく性能が向上することが報告されています。
ここでは、以下に現状よく使われている深層学習ベースの音源分離手法について
・Permutation invariant training(PIT)
混合音声の分離には、話者の分離順序の問題があります。具体的には、「AさんBさんの順序」で分離するよう学習したモデルと「BさんAさんの順序」で分離するよう学習したモデルが別物として扱われてしまいます。
PITでは、モデルが異なる話者に対応する複数の出力層を持ち、すべての組み合わせを考慮してモデルを訓練します。つまり、「AさんBさんの順序」と「BさんAさんの順序」の両方を計算し、最適な方を選ぶということをします。
PITは、2020年現在、よく使われている手法ですが、課題もあります。すべての組み合わせを計算しなければならないため、話者数が2人、3人、4人…と増えるごとに、順列組み合わせは、2通り、6通り、24通り…というように計算量が爆発します。
Kolbæk, Morten, et al. "Multitalker speech separation with utterance-level permutation invariant training of deep recurrent neural networks." IEEE/ACM Transactions on Audio, Speech, and Language Processing 25.10 (2017): 1901-1913.
・Deep clustering
PITと同様に、話者の分離順序問題(パーミュテーション問題)を解決するため、Deep clusteringという手法が提案されています。
この手法は、入力された混合波形を深層学習モデルによって、Embedding空間と言われる特徴空間にマッピングを行います。Embedding空間では、同一話者間では近い領域に、異なる話者間では遠い領域にマッピングされるよう学習が行われます。次に、k-meansのようなクラスタリング手法を用いて、話者ごとにマッピングされた特徴量を分離します。
この手法の課題は、k-meansのようなクラスタリング手法が必要なところです。k-meansでは、あらかじめ話者数を指定しておく必要があるのですが、多くの場合、話者数は未知もしくは変化します。
したがって、別途、話者数を推定するような手法が必要になります。
Hershey, John R., et al. "Deep clustering: Discriminative embeddings for segmentation and separation." 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2016.
まとめ
音に関する研究について、電話品質向上をルーツからまとめました。また、深層学習ベースの音源分離手法について、よく使われる手法とその課題についてまとめました。
たしかに、最近のAI技術はかなりの進歩を見せており、「AIにデータ食わせれば何でもできちゃうんでしょ?」というように言われる方も多いですが、一般的には知られていないような解決すべき課題を一つずつクリアしていった結果、今に至っているということもわかりました。
知識も経験もまだまだな私ですが、残っている課題の1つでも解決できるよう、博士課程の研究に邁進していければと考えております!