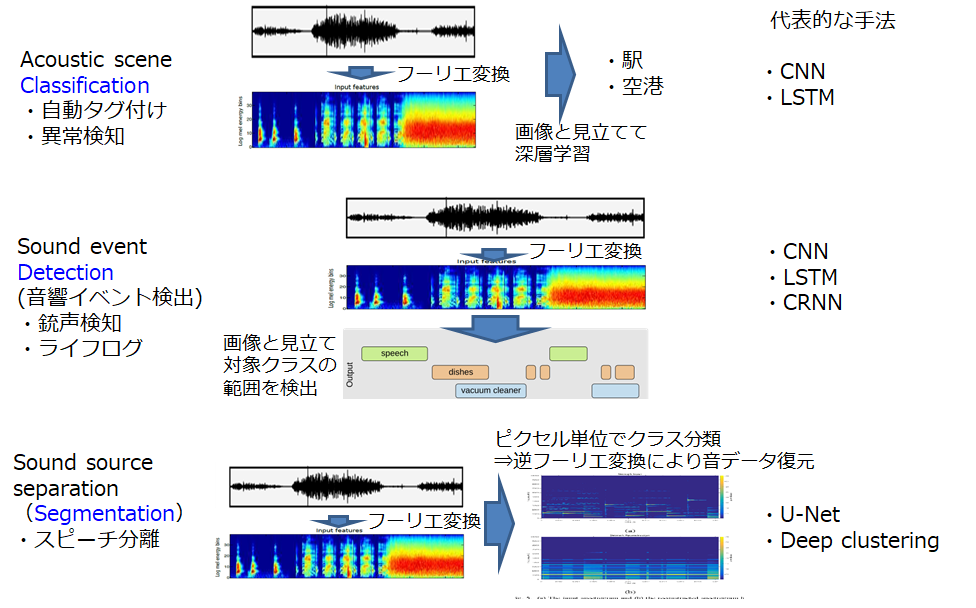
以前、画像と音を使ったディープラーニングタスクには類似性があるということを書きました。
今回は、学習データの集め方について、画像と音について比較してみようと思います。
結論から述べてしまうと、画像と音では、学習データの集め方には大きな違いがあります。特に、音データの場合、正解ラベルを付ける手間非常に大きいです。
画像を使ったディープラーニング用データの集め方
画像を使ったディープラーニングと言ってもさまざまなタスクがありますが、クラス分類、物体検出、セマンティックセグメンテーションといった、基本的なタスクについては、人が画像を見て、予測させたいものの正解ラベルをつけていきいます。
クラス分類: 1枚の画像に対し、それが犬なのか猫なのか、1つのラベルを付与するタスクです。
人が目で見て、決められたラベルを付与します。今回紹介するタスクの中では最も手間の少ないアノテーションです。
物体検出:ある物体が画像の中で、どこにあるのかをBounding boxという四角い枠で検出するタスクです。
クラスのラベルだけでなく、バウンディングボックスを正解ラベルとして与えてやる必要があります。バウンディングボックスが大きすぎても小さすぎても学習に悪影響を与えてしまうので、かなり手間がふえてしまいます。さらに、クラス分類タスクと異なり、物体の個数に制限がないので、ラベルのつけ忘れにも注意する必要があります。
セマンティックセグメンテーション:物体検出のようにバウンディングボックスで囲むのではなく、ピクセル単位でクラス分類を行うタスクです。
このタスクのためのラベル付は、さらに手間がかかります。各物体の縁をきれいに塗り絵をするように、1ピクセルずつラベルを付けていく必要があります。物体検出同様、物体の数が1個とは限りませんし、物体同士が重なっている場合は特に注意して塗り絵を行う必要があります。また、自転車の車輪などのように、安易に内側を塗りつぶすことができないような物体も、非常に手間がかかります。
音の学習データの集め方
環境音認識に関するタスクも同様に以下のように分類することができ、多くの研究では、前処理として時系列波形を短時間フーリエ変換することで、2次元の「画像」と見立てて、ディープラーニングに適用します。では、それぞれに必要なラベル付け作業について書いていきます。
シーン分類:画像のクラス分類に相当するタスクです。数秒〜数十秒程度の音データに対し、駅や空港などといった、1つのシーンを表すラベルを付与します。画像であれば、1秒でラベルを判断できますが、音の場合、聞いてから出ないとラベル付けができないので、その分時間がかかります。また、そもそも、カメラのように連写のようなことができないので、収録したい時間の分だけ時間が必要です。
音響イベント検出:画像の物体検出に相当するタスクで、いつどのクラスの音が鳴っていたかを検出します。シーン分類に比べて、さらにラベル付けの手間がかかります。特に、徐々に音量が小さくなっていくような音の場合、どこまでをそのクラスの音がアクティブとみなすかはラベル付けを行う人によってばらつきが出てしまいます。さらに、複数の音が重なって鳴っているような区間の場合、どちらかを聴き逃してしまう可能性もあります。
音源分離:画像のセマンティックセグメンテーションに相当するタスクです。特定のクラスの音のピクセルだけを取り出すことができれば、逆フーリエ変換することで、特定のクラスの音だけを取り出すことができます。
このタスクに関しては、人がラベル付けを行うことが不可能です。というのも、以下の図市場下の段が音源分離タスクを示していますが、短時間フーリエ変換画像に対して、1ピクセルごとに塗り絵を行っていかなければなりません。フーリエ変換画像を見たところでどのピクセルがどのクラスの音に相当するのか、見て判断することはできませんし、仮にできたとしても、複数の音が同時になっている部分を塗り分けることができません。
では、聞きたい音だけを取り出すAIはどのように学習させているでしょうか?次のセクションで詳しく説明します。
音源分離のための学習データ収集
特定の音だけを取り出すAIの研究は盛んに研究されています。
例えば、雑音にまみれた音声から、クリーンな音声のみを分離する研究や、複数の発話から、特定の話者の音声を分離する研究などがあります。
しかし、先程も述べたように、混合音のフーリエ変換画像から、特定の音のピクセルだけをアノテーションすることは不可能なので、どのように学習データを作っているでしょうか?
正解は、多くの研究テーマでは、事前に録音したクリーンな音声とそれ以外の音声やノイズを合成して、学習データを作成している研究が多いです。
具体的には、以下の上3つのように、個々の音声を録音しておき、コンピュータ上で下のように合成します。合成前のデータを正解データとして、混合音から特定の音声を取り出すモデルを学習させることができます。
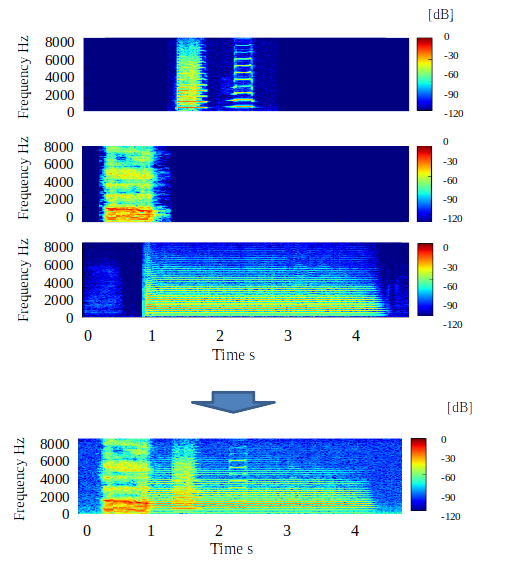
この手法を用いることで、比較的容易に音源分離のための学習データを集めることが可能になります。
しかし、この方法には問題点もあります。まず、事前にその音単体のクリーンな音源が取れるかどうかという問題があります。音声であれば、マイクの近くで話してもらえばクリーンな音声が録音できますが、鳥の鳴き声や雷の音などは、必ずしも単体でクリーンな音が収録できるとは限りません。
また、限られた状況で録音した音のみで学習したモデルは、実際の環境でうまく動作するかどうかもわかりません。
したがって、手法そのものとしては、画像と音に類似性があると言えるかもしれませんが、音には音ならではの研究課題があると言えます。特に、音源分離に関しては、高品質な正解データを大量に集めることに課題があると言え、簡易なラベルで音源分離を行う手法も提案され始めてきました(2020年現在)。
まとめ
今回は、ディープラーニングのための学習データの集め方について述べました。
画像も音も、大量のデータを集めるのは大変ですが、音のデータの方がより集めるのに時間がかかり、さらに、音源分離用のデータ収集には、かなりの制限があることがわかりました。
AIで何でもできちゃうんじゃないの?的な風潮もあったりしますが、研究にしろ開発にしろ、オリジナリティを持たせるためには、対象アプリ特有の課題は何か?ということを捉えることは非常に重要なように思います。