【サーベイ】深層学習を用いた音源分離手法のまとめ
はじめに
近年、深層学習を用いた様々な音源分離手法が提案されており、性能が向上することが
多数報告されています。
音源分離手法は、マイクロフォンの数やベースとなっている手法に応じて、大きく4つに分類することができます。
以下の表は、マイクロフォンの数(シングルorマルチ)およびベースとしている手法(信号処理ベースor深層学習ベース)ごとの代表的な手法を示しています。
本記事では、シングルチャンネルマイクを対象とした、深層学習ベースの手法のサーベイを行います。

音源分離性能向上の推移
以下の図は、年ごとの音源分離性能の推移を示しています。
2015年以前は記載されていませんが、Deep clusteringとConv-TasNetがブレイクスルーになったと言われています。

以降の節で、Deep clustering以前に提案されたU-Netを用いた音声分離を含め、各手法について説明します。具体的には、以下のモデルについて説明します。
・U-Net
・Deep clustering
・Conv-TasNet
U-Netを用いた音声分離
以下の図は、全体概要を示しています。まず、歌声、伴奏が混ざった音源に対し、短時間フーリエ変換を行います。短時間フーリエ変換では、複素数の結果が得られるので、振幅、位相スペクトルに分解します。そのうち、振幅スペクトルを画像と見立てて、セマンティックセグメンテーション手法の1つであるU-Netに適用します。
U-Netでは、歌声と伴奏を分離するようなマスク画像を予測します。
しかし、得られた歌声のみの振幅スペクトルだけでは、時系列信号を復元することができません。そこで、混合音のSTFTから得られた位相スペクトルを用いることで、歌声のみの時系列波形を復元することができます。厳密には、混合音の位相スペクトルは、歌声のみの位相スペクトルとは異なるのですが、聴感的にはそれなりの音源が分離できます。

Duyeon Kim, Jaehoon Oh. “vocal separation from songs using deep convolutional encoder-decoder networks, GCT634 , KAIST, Korea, 2018.
実際に学習が行われるU-Netについて、詳しく説明します。U-Netはエンコーダデコーダ構造をとっており、各層の間にスキップ結合をもつことで、高解像度なセグメンテーション画像を予測することを狙ったネットワークです。
画像のセマンティックセグメンテーションとの違いは、歌声の振幅スペクトルを直接予測するのではなく、入力画像と掛け算することによって、歌声のみを取り出すマスク画像を予測する点が異なります。
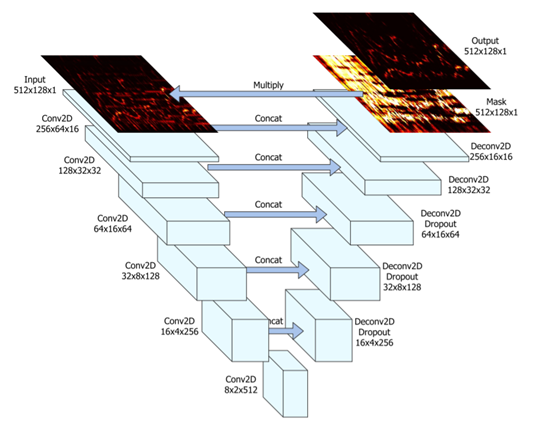
Andreas Jansson, Eric J. Humphrey, Nicola Montecchio, Rachel Bittner, Aparna Kumar, Tillman Weyde, Singing Voice Separation with Deep U-Net Convolutional Networks, Proceedings of the 18th International Society for Music Information Retrieval Conference (ISMIR), 2017.
Deep clustering
U-Netを用いた歌声分離では、音声とそれ以外という明確に異なるクラスに対し、学習を行っていましたが、複数話者の音声が混合していた場合、うまく学習することができません。
パーミュテーション問題と呼ばれますが、話者Aと話者Bが入れ替わっていても問題ないが、ニューラルネットワーク内では区別して学習が行われてしまうため、性能が劣化してしまいます。
これに対し、Deep clusteringでは、以下のように問題を解決しています。
入力されたスペクトログラムの特徴量が、ニューラルネットワーク内でembedding空間へと写像されます。
話者の異なる特徴量はが互いに遠くに配置されるよう、embedding空間への写像関数が学習されます。
このように、話者を意識することなく学習を行うことができるようになったため、1つのブレイクスルーとなりました。

Conv-TasNet
U-NetやDeep clusteringでは、短時間フーリエ変換を行うことが前提となっていましたが、従来の手法では、振幅スペクトルしか学習に用いておらず、分離音の位相を予測することができません。
そのため、仕方なく混合音の位相を使って時系列信号の復元を行っており、位相の情報が正確でないことによって、復元された音に歪が残ってしまうという問題がありました。
そこで、時系列信号をそのままニューラルネットワークに入力する、Conv-TasNetという手法が提案されています。
以下の図は、Conv-TasNetの概要を示しています。Conv-TasNetは、Encoder, Separation, Decoderの3つから構成されています。
Encoder: 従来短時間フーリエ変換に頼っていた特徴抽出を学習によって行う
Separation: 抽出された特徴量に対し、各音源の特徴をマスクする
Decoder: 音源ごとに分離された特徴量に対し、時系列信号の復元を行う。
時系列信号をそのまま入力するため、位相の情報も暗に学習されていることが期待されます。

Y. Luo and N. Mesgarani, “Conv-TasNet: Surpassing ideal timefrequency magnitude masking for speech separation," IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP), vol. 27, no. 8, pp. 1256-1266, 2019.
そして、学習後のネットワークの第1層目を見てみると、以下の図のように、分離に最適なバンドパスフィルタが学習されていることが報告されています。

M. Ravanelli and Y. Bengio, “Speaker recognition from raw waveform with sincnet," IEEE Spoken Language Technology Workshop (SLT), 2018, pp. 1021-1028.
まとめ
本記事では、シングルチャンネルマイクを前提とした、深層学習ベースの音源分離手法のサーベイを行いました。
参考文献