本記事では、別々のコーパスで学習されたモーダルの異なるモデルを接続する際のAdaptation方法を提案した論文を紹介する。
本論文は、Visual encoderと言語モデルから構成されるvisual story tellingを題材にしているが、音声認識モデルにおける音響モデルと言語モデルでも同じことがいえるのではないかと考えられる。
概要
視覚から言語への変換を行う従来のモデルでは、視覚エンコーダーと言語ジェネレーターをそれぞれの領域で事前に学習させ、ターゲットタスクに合わせて共同で微調整するのが一般的である。
しかし、このような直接的な伝達方法では、視覚的な特異性と言語的な流暢性との間に不一致が生じる可能性がある。なぜなら、これらは共通の基盤を持たない大量の視覚データとテキストデータのコーパスから別々に学習されることが多いからである。
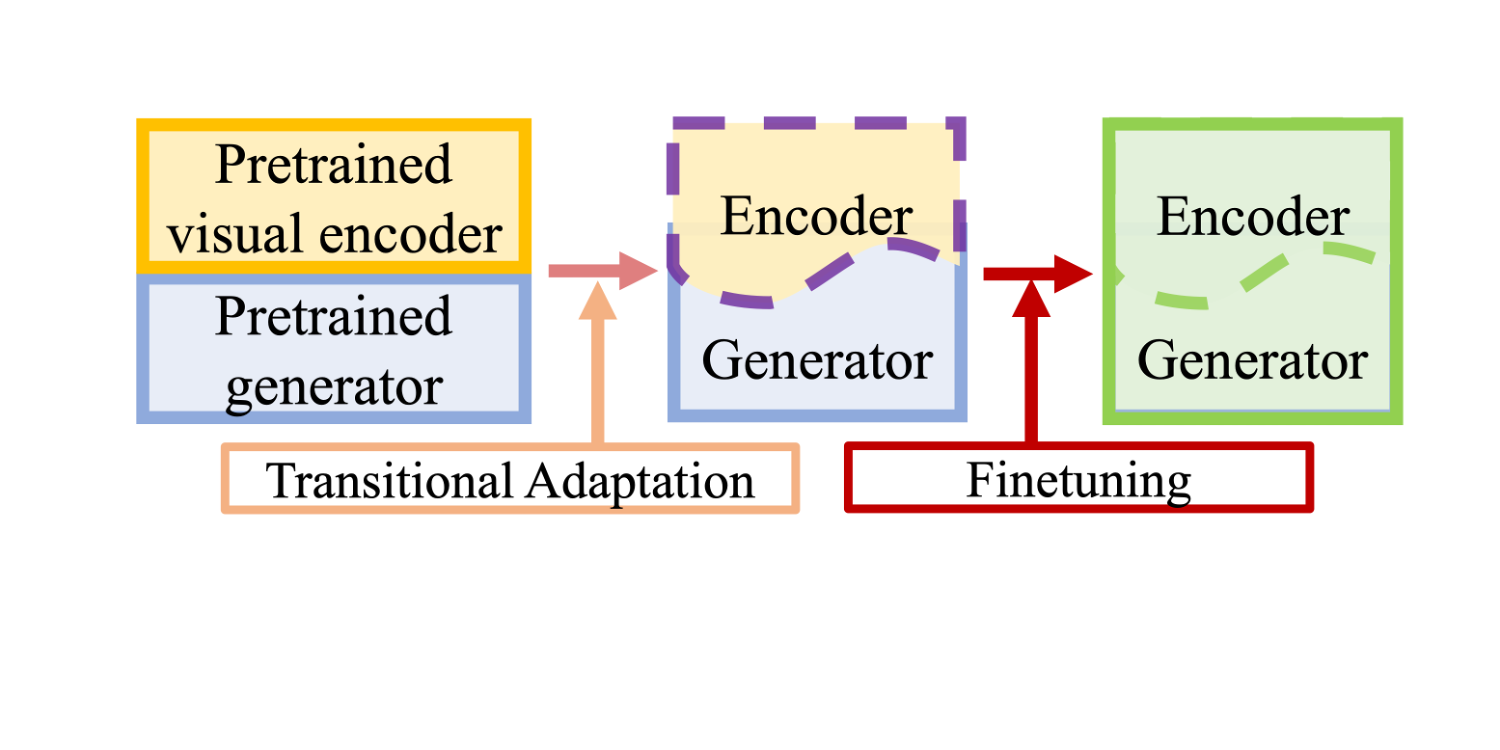
本研究では、ビジュアルストーリーテリングのような挑戦的な下流のターゲットタスクにおいて、ビジュアルエンコーダーと言語モデルを調和させるためには、事前学習と微調整の間に過渡的な適応タスクが必要であると主張する。
本研究では、TAPM(Transitional Adaptation of Pretrained Model)と呼ばれる新しいアプローチを提案する。このアプローチでは、テキストラベルを必要とせず、視覚的な入力のみのシンプルなアライメントタスクによって、マルチモーダルモジュールを相互に適応させる。
大規模な実験により、この適応ステップが、連続するビデオや画像のキャプション作成タスクにおける複数の言語モデルの性能を大幅に向上させることを示した。
Introduction
視覚から言語への変換を行うモデルの多くは,入力画像や動画から視覚情報を抽出する視覚エンコーダーと,テキスト文を生成する言語モデル,そして,これら2つのモジュールを1つの調和のとれたアーキテクチャに融合させるメカニズムから構成されている.
しかし、このプロセスでは、視覚エンコーダーと言語生成器に格納されている情報の間に潜在的に大きな違いがあることに対応するための過渡的な適応ステップは提案されていない。
これは、共通の基盤を持たない大規模な視覚データとテキストデータのセット(例えば、ImageNetの画像とWikipediaのテキスト)から別々に学習されているためである。
事前に学習した言語モデルを別のターゲットタスクで微調整すると、言語生成能力が壊滅的に忘れられてしまう可能性がある。
そこで我々は、ビジュアルストーリーテリングのためのTAPM(Transitional Adaptation of Pretrained Model)を提案する。これは、ビジュアルエンコーダと事前に学習された言語モデルを調和させるために、明示的な視覚適応ステップを提案する最初のアプローチである。この適応ステップは、テキストラベルのない画像やビデオなど、視覚的な入力のみで学習することができる。
本研究の貢献は以下の通りである。
1. 事前学習された言語モデルを用いてビジュアルエンコーダを溶接する際に、補助的な適応損失の有効性を実証した。大規模な実験により、事前学習と微調整の間のこの追加的な適応が、様々な言語モデルのキャプション品質を一貫して向上させることを示した。
2. 逐次コヒーレンス損失(sequential coherence loss)を用いて、テキストラベルのない逐次的なビデオや画像の入力のみを用いて言語生成器を適応させることができる。
3. TAPM を 2 つのストーリーテリングタスクで評価した。TAPMは自動言語メトリクスと人間の評価の観点から、新たに最先端の性能を達成した。
Approach
全体のアーキテクチャは,ビジュアル・エンコーダと言語生成器で構成されている.
ビジュアルエンコーダと言語生成器を適応損失で訓練した後、下流のキャプション作成タスクで微調整する。
アダプテーションロスには、シーケンシャルコヒーレンスロスを採用し、シーケンシャルキャプションの識別性と一貫性を高めている。これらの損失は、言語モデルの出力に適用され、言語モデルに従ってビジュアルエンコーダを更新する。
最後に,エンコーダーとジェネレーターを,ビジュアルストーリーテリングという目標に向かってトレーニングする.
Visual Encoder
ビデオクリップが与えられたとき,事前に学習させた特徴抽出器を用いて,各フレームjのベクトル特徴vijを抽出する.次に,ベクトルを時間軸方向に平均化することで,M個のセグメントに分割する.抽出されたビデオクリップの特徴量を入力とする。
Language Generator
言語生成器には,任意の言語モデルを用いることができる.800万のウェブページからなるコーパスデータセットで事前学習したGPT-2-smallをデフォルトの生成器として使用している.
Adaptation training
適応段階で言語生成器と調和させるために、単純な補助目的で視覚エンコーダーを訓練する。ここでは、ビデオ入力に対する適応損失を計算するために、視覚表現とテキスト表現をエンコードする方法を説明する。
適応段階では、モデルはビデオのみを入力とする。ビデオが与えられると,言語生成器は,各ビデオに対応するビデオエンベッディング(Vi)とテキストエンベッディング(Si)を構築する.
Sequential Coherence Loss
連続した画像やビデオクリップには、共通の背景、キャラクター、オブジェクトなどがある。そのため、それらの視覚的特徴が類似しており、結果として、それらから生成されるキャプションは互いに重なり合う。
そこで、ビジュアル・ストーリーテリング・タスクにおける時間的コヒーレンスを向上させるために,Sequential Coherence Lossを導入する.
まず、それぞれのFCレイヤーを用いて、テキスト埋め込みを過去、現在、未来の視覚空間に投影する。そして、過去、現在、未来のそれぞれのテキスト埋め込みを、他の視覚表現(Push(赤矢印))よりも、対応する視覚表現(Pull(緑矢印))に近づけるようにする。
![PDF] Transitional Adaptation of Pretrained Models for Visual Storytelling | Semantic Scholar](https://d3i71xaburhd42.cloudfront.net/5c52e6a85cb3f68804bf0c875e88fa2f44160220/4-Figure2-1.png)
Conclusion
我々は、視覚から言語への生成タスクにおいて、事前に学習された言語モデルと視覚エンコーダーを調和させるためのTransitional Adaptation of Pretrained Model (TAPM)手法を提案した。
広範な実験により、適応損失を用いた適応段階は、いくつかの言語モデルと損失タイプの間で一貫してキャプションの品質を向上させることが示された。
この研究の先にはいくつかの方向性がある。
第一に、多くの言語タスクでその強さが証明されている事前学習済みの言語モデルの視覚的理解能力を向上させるために、他の適応損失タイプを探索することができる。
第二に、視覚的なストーリーテリング以外にも、事前学習された言語モデルを利用した他のクロスモーダルな生成タスクに本研究の手法を適用することができる。