音響イベント検出とは
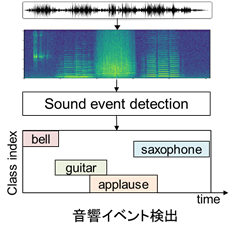
音響イベント検出とは、環境音認識のためのタスクで、以下の図のように、音データの中から特定の音響イベントの発生区間を検出するというものです。
図の下側のように、「○○秒~○○秒にギターの音が鳴っている」といったことが、自動で分かるようになります。
これができると何がいいのか??
→アメリカではすでにAmazon guardというAlexaのサービスが始まっているのですが。ユーザーが外出中のガラス破損音など、侵入者などの異常と思われる音響イベントを自動で検知して、スマホにお知らせしてくれたりします。
Amazon guard(アマゾンが具体的にどのようなアルゴリズムを使っているかはわかりませんが。)
CNNとRNNを組み合わせたCRNNを用いた音響イベント検出
ここで、ようやく今回の主題です。今回は、現在のところ、よく使われる深層学習ネットワークである、CRNN(Convolutional Recurrent Neural Network)という手法について紹介します。その名の通り、CNNとRNNを組み合わせた手法で、それぞれを単体で使うよりも、性能が向上します。
具体的には、時系列波形である音の信号を短時間フーリエ変換(STFT)によって2次元画像に変換し、CNN、RNNに入力します。

CNN、RNNの長所・短所
短時間フーリエ変換して得られた2次元画像=スペクトログラムに対し、CNNとRNNを適用するわけですが、それぞれ、以下の長所と短所が存在します。
ここで、スペクトログラムにおいて、横軸が時間、縦軸が周波数、色が赤いほど音圧が強いことを示しています。
短時間フーリエ変換の詳細については、別の記事で詳しく書いたので参考にしてください。
CNN
長所:スペクトログラム上で縦横3x3のフィルタを使って畳み込みを行うので、ある程度の時間方向・周波数方向の関係性が学習可能です。時間方向の関係性は、「前後の音から今の音響イベントを推測する」ために学習されます。周波数方向の関係性は、いわゆるその音の音色を学習することに相当します。
短所:図左側の赤四角が畳み込みのフィルタを示していますが、スペクトログラム画像全体に比べ、ごく小さなフィルタでしか畳み込むことができず、短い時間の関係性しか学習することができません。
RNN(LSTM)
長所:LSTMの特徴でもありますが、長時間の関係性を学習することが可能です。
短所:時間方向の関係性しか学習しないネットワーク構造になっているので、周波数方向の関係性は一切学習できない

得られた結果
では、CNN、RNN、CRNNの結果を比較してみます。
上から、入力スペクトログラム、音響イベントの正解、CNN, RNN, CRNNの予測結果の順で並んでいます。横軸が時間、縦軸はクラスインデックス(犬や拍手など)、赤い部分がそのクラスの音が鳴っていることを示しています。それぞれの結果について議論したいと思います。
まず、CNNに関してです。正解ラベルと比較し、大まかな傾向は予測できているといえますが、結果がノイジーでバタついています。これは、CNN単体では長時間の関係性が学習できていないので、「直前が鳴っていたので、今もなっているはずだ」といったような前後の音を考慮した推測ができていないと考えられます。
一方、RNNは、CNNに比べると結果にバタつきは見られませんが、周波数方向(すなわち音色)を学習できていないので、クラスそのものを間違えて予測しています。
それに対し、CRNNでは、CNN,RNNそれぞれの短所を補い合うことができており、正しいクラスを予測しながらも、バタつきが少なくなっています。

実装例
以下は、python、kerasを使ったCNNの実装例ですが、非常に簡単に実装することができます。

評価実験
後に示す結果例のように、さまざまなクラスの混ざった混合音のスペクトログラムに対し、CRNNを実行。
結果は以下の通り。なお、結果の横軸は時間(STFTフレーム数)、縦軸はクラスインデックスを示す。(インデックスとクラスの対応は記載していません。。)
RNNはうまく動かなかったので載せていないが、CNNとCRNNを比較すると、
論文の通り、CNNは結果がバタついているのに対し、CRNNはきれいな結果が出ている。




まとめ
今回は、音響イベント検出のネットワークとしてよく使われるCRNNを紹介しました。
・CNNとRNNを組み合わせたCRNNは、それぞれのいいとこどり
CNN:「音色」が学習可能だが、長時間の関係性は学習できない
RNN:長時間の関係性は学習できるが、周波数の関連性(音色)が学習できない
※その後の調べで、どうやらアマゾンエコーにも使われていることがわかりました。
よければそちらの記事もご覧ください。