今回は、アマゾンエコーに搭載されているAlexaの開発チームによる、Speech Emotion Recgnitionについて書きます。リンク先のニュースでも紹介されているようにアレクサは今後さらに感情表現や認識ができるようになっていくだろうと思います。
https://forbesjapan.com/articles/detail/30999
そこで、2019年6月に開催された、「Amazon Re: MARS」というワークショップにてプレゼンされていたSpeech Emotion Recgnitionについて、以下のyoutube動画をもとに勉強しましたので、解説してみようと思います。図はリンク動画から引用させていただきました。
https://www.youtube.com/watch?v=26_qiXEa8lw
なぜ感情認識が必要なのか?
この動画では具体的には語られていませんでしたが、人間はAI対して、かなり自分の感情を表現するようです。たしかに、ソニーのAiboのようなコミュニケーションができるロボット近年売れていると聞いたことがあります。したがって、よりよいコミュニケーションを実現するために、AIは感情を認識できるようにならなければならないとのことです。
また、いわゆるコミュニケーションとまではいきませんが、運転中の疲労検知も感情認識に関連する重要な技術で、一部導入されていますね。

感情認識の定義
では、感情認識をするといっても、AIのような機械がそれを行うためには、ちゃんとした定義が必要ですが、どういった形で出力すれば適切に感情を認識できたといえるのでしょうか。
よく使われているのが以下の図左側のように、怒り・幸せ、悲しみなどのようにいくつかのクラスに分類する手法があるそうです。しかし、この手法の問題点は、Anger(怒り)とDisgust(嫌悪)のように非常に似た感情があり、必ずしもきれいに分類できる場合ばかりではない点です。
図右はそれをValence、Activation、Dominanceという3次元空間で感情を定義しようというものです。3つの軸が何を表しているのか、抽象的で理解が難しいですが、この感情次元という手法を使うことで、図左のような感情に対し、程度も表現することが可能になります。

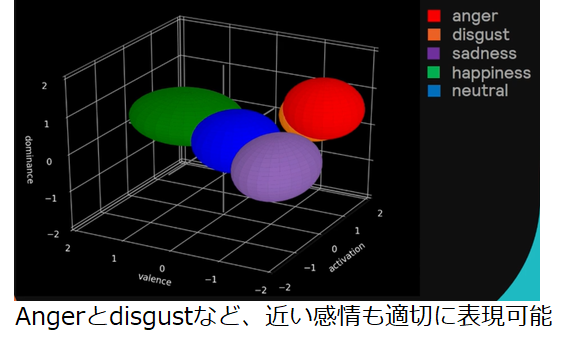
以下の図は、感情次元で表現された感情の例です。AngerとDisgustといった似た感情も適切に表現できています。また、同じHappinessであったとしても、その感情がどの程度強いのかといったことも表現することができます。デメリットとしては、AIに学習させようと思った際に、これらの教師データを作成する手間が非常にかかる点だそうです。
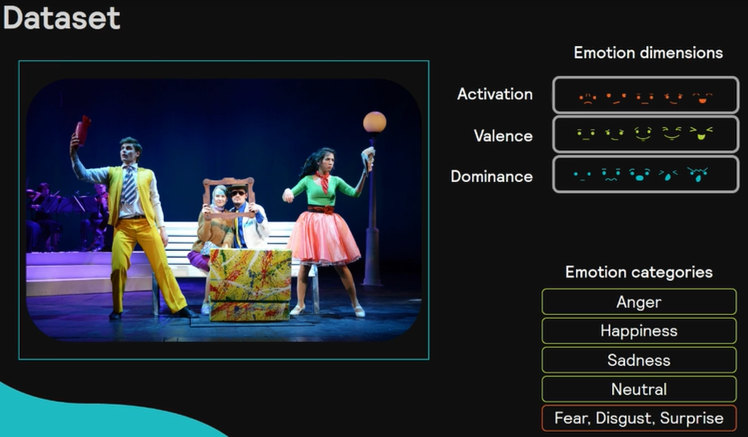
データセット
データセットの作り方についても述べられていました。様々なポッドキャスト、ラジオ、動画などに対して、クラウドソーシングで図右のような感情ラベルを付けたデータセットを作成するようです。
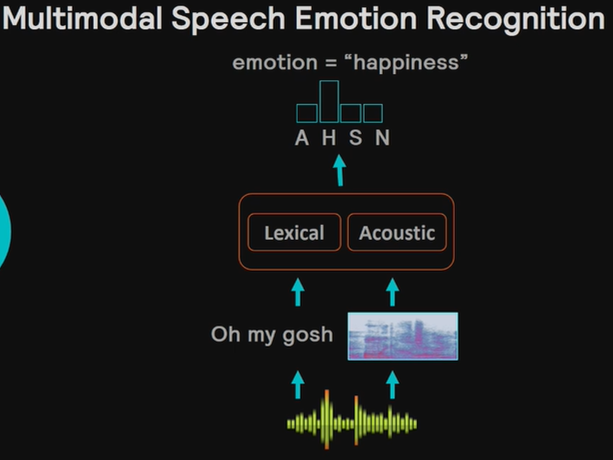
ネットワーク概要
動画ではいくつかの深層学習ネットワークが紹介されていたが、ここでは1つだけ紹介します。
音声認識を用いた単語の特徴と、フーリエ変換を使った周波数特徴の2つのモーダルを使うことで、感情認識の精度を向上させるというネットワークです。
例えば、oh my goshという言葉自体の意味とその言い方や音色の両方から、感情を推定しようとします。
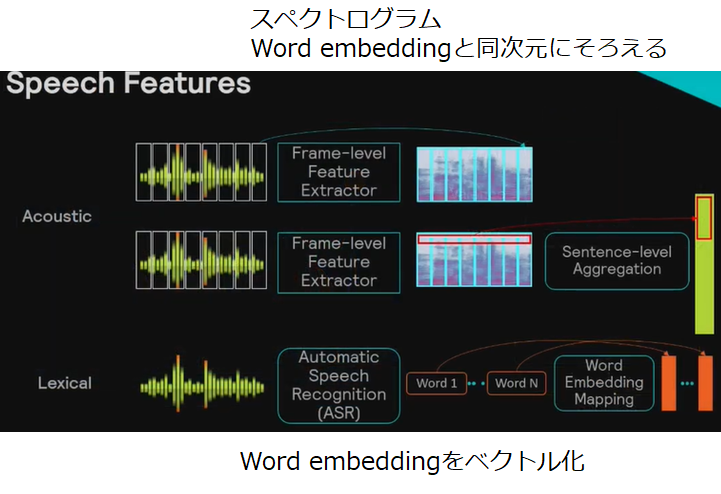
単語特徴と音響特徴の抽出方法
単語特徴には、すでに学習された音声認識ネットワークを使用して、Word embeddingを使用します。Word embeddingというのは、単語をベクトル表現したものです。
音響特徴には短時間フーリエ変換を用います。動画では述べられていませんでしたが、おそらくメルスペクトログラムではないかと思っています。
ネットワーク構成
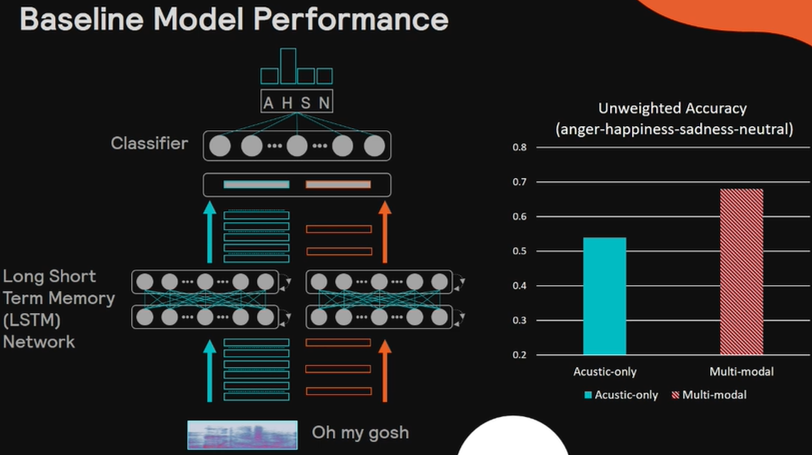
単語特徴と音響特徴はLSTMに入力され、それら両方を使って感情分類を行います。
動画の序盤では感情空間を使った感情表現について説明されていましたが、この論文では、普通のクラス分類が使われているようです。
図右に音響特徴のみから感情推定した場合と単語特徴と音響特徴両方を使った場合の正解率を示しています。図の通り、2つ両方使うことで、より正確な感情認識ができていることが分かります。
ネットワークの改良
上の結果だけでも、性能は向上しているのですが、まだ課題があるそうです。
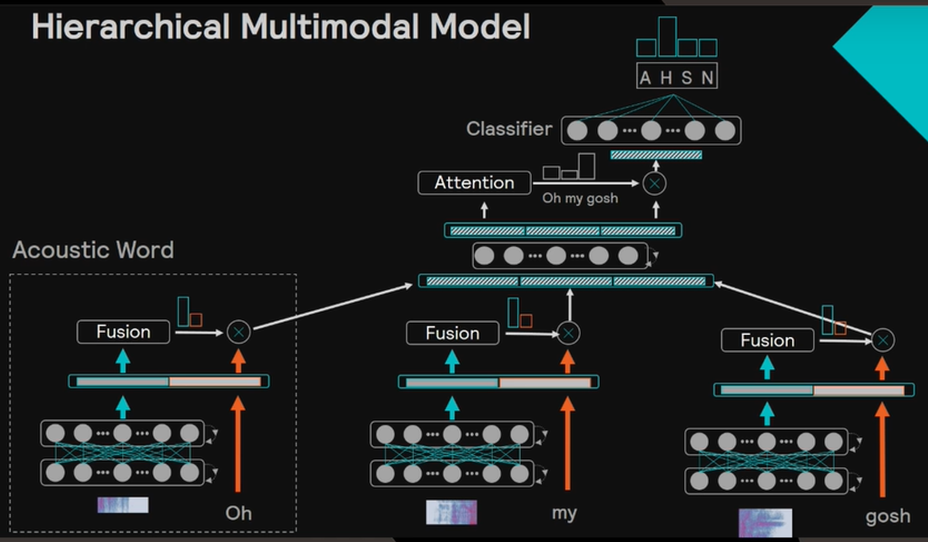
例えば、「Oh my gosh」という言葉が認識された場合、「gosh」に最も感情の情報が集中しているはずですが、上のネットワーク構成では、どれも同じ重みで学習されています。
そこで、動画では、以下のネットワーク構成が提案されています。複雑で理解しにくいですが、重要な点はAttentionを用いているという点です。
Attentionとは、翻訳などに使われているテクニックで、注目すべき単語を強調させる効果があります。
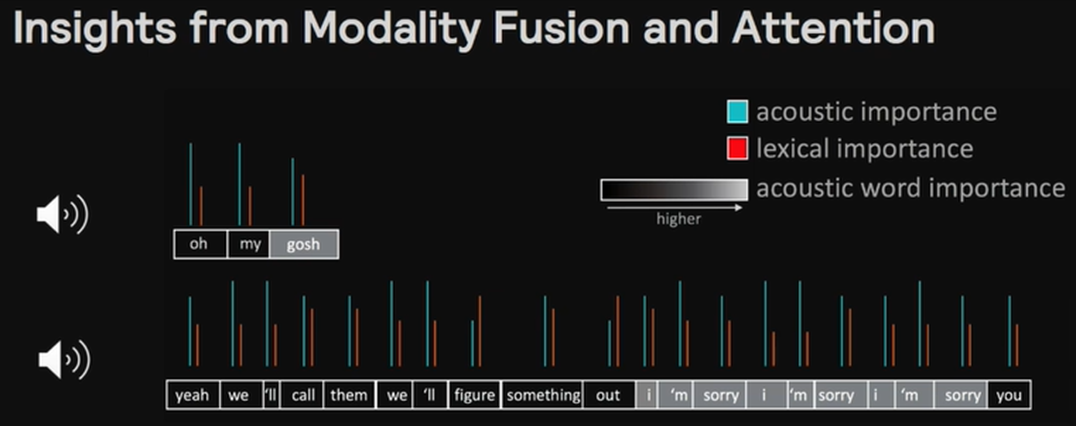
実際にAttentionにより強調された単語を見てみましょう。「gosh」の部分やI'm sorryといった感情に直結する部分を強調して学習することができています。
実験結果
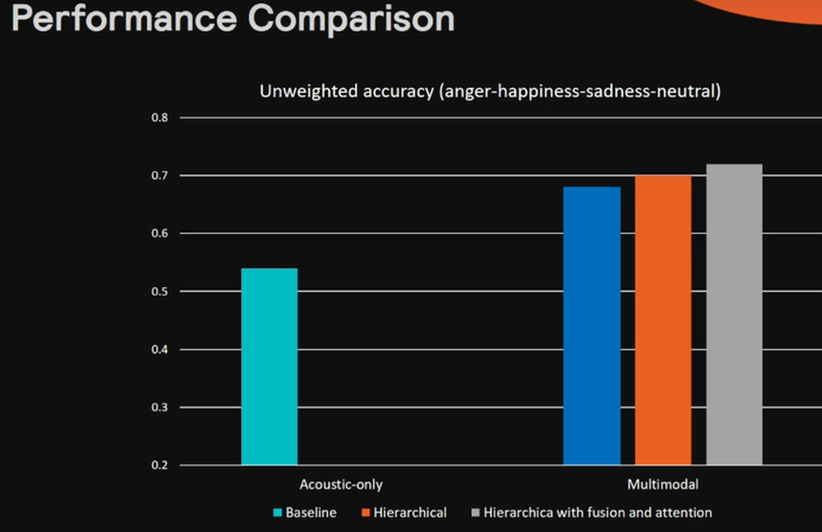
以下が最終的な感情認識の結果です。マルチモーダルにするだけでも、性能は向上していますが、Attention機構を導入することで、さらに精度が改善されています、
まとめ
Amazon Re: MARSのプレゼン動画をもとに、Speech emotion recognitionについて調査しました。
・Happiness, sadnessのようなクラス分類タスクによるラベリングだけでなく、Valance, Activation, Dominanceの3次元空間による表現を使うことで、Disgust, Angerのような似た感情も適切に表現が可能(ラベル付け工数は大きくなるが)
・Acoustic featureだけでなく、音声認識を用いたLexical featureとのマルチモーダルを提案
・階層構造、Attentionを用いることで、「Sorry」など感情認識に重要な単語を効率的に学習できるネットワークを提案
これ以外にも、アマゾンエコーの防犯機能について解説しています。よければそちらもご覧ください。
ご意見、ご質問、調べてほしいことなどあれば、コメントください。
励みになりますので、お気に入り登録もよろしくお願いいたします!